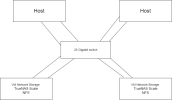
We want to assemble the following virtualization scheme.

I need advice on the scheme itself and how to properly organize reservations.
It is clear that Proxmox BackUP Server is also missing here.
But it is not very clear to me how to act in case of failure of one of the VM Storage
If we have a backup server, then we can restore on the second VM Storage, but it takes a very long time.
There is a similar scheme on XCP-NG, and there we implemented it by simply doing continuous replication from one VM Storage to another using XOA every night. Won't it work on proxmox?
How to organize it correctly?
By replicating TrueNAS itself from one to another? Will this work correctly if all the machines are running on proxmox? And will proxmox normally see all these machines on the second storage? As far as I remember, there are some nuances when replicating TrueNAS with rights to objects where it is replicated, although I may be confusing something...
I need advice on the scheme itself and how to properly organize reservations.
It is clear that Proxmox BackUP Server is also missing here.
But it is not very clear to me how to act in case of failure of one of the VM Storage
If we have a backup server, then we can restore on the second VM Storage, but it takes a very long time.
There is a similar scheme on XCP-NG, and there we implemented it by simply doing continuous replication from one VM Storage to another using XOA every night. Won't it work on proxmox?
How to organize it correctly?
By replicating TrueNAS itself from one to another? Will this work correctly if all the machines are running on proxmox? And will proxmox normally see all these machines on the second storage? As far as I remember, there are some nuances when replicating TrueNAS with rights to objects where it is replicated, although I may be confusing something...
Attachments
Last edited:

") The number of machines to start with is 25 pieces, linux and windows, they will also use mssql databases and others.
The number of machines to start with is 25 pieces, linux and windows, they will also use mssql databases and others.