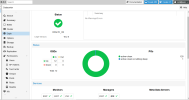
Hi all, we deployed a proxmox cluster with 3 nodes last year and it was running relatively ok and we are getting quite familiar with the system.
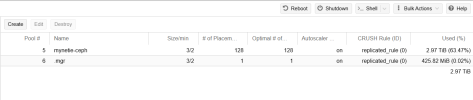
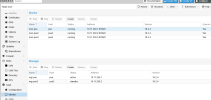
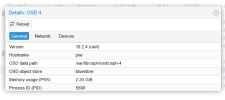
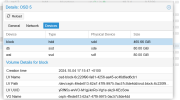
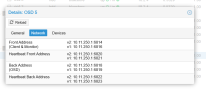
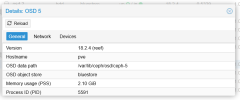
The storage is ceph shared strorage with 12 OSD's across 3 nodes (4 each). We have just in the last week deployed a new software which runs an informix database which does checkpoints on write speeds on the disks. It is failing these checkpoints and causing major issues operationally. It is a monitoring software so we have operators working on the client software 24 hours per day. It is causing severe issues and crashing for them so is now quite urgent.
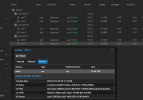
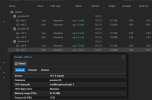
We have Kingston DC600M SSD Drives for DB & Wal and the rest of the storage is made up of western Digital Gold Data center drives.
According to the companies support they are seeing checkpoints take 60 seconds at times which should take maximum of 10 seconds to complete and they are telling us it is disk related due to write speeds.
Any idea how we could troubleshoot such an issue?
The storage is ceph shared strorage with 12 OSD's across 3 nodes (4 each). We have just in the last week deployed a new software which runs an informix database which does checkpoints on write speeds on the disks. It is failing these checkpoints and causing major issues operationally. It is a monitoring software so we have operators working on the client software 24 hours per day. It is causing severe issues and crashing for them so is now quite urgent.
We have Kingston DC600M SSD Drives for DB & Wal and the rest of the storage is made up of western Digital Gold Data center drives.
According to the companies support they are seeing checkpoints take 60 seconds at times which should take maximum of 10 seconds to complete and they are telling us it is disk related due to write speeds.
Any idea how we could troubleshoot such an issue?









")