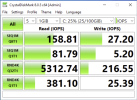
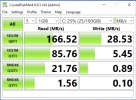
My understanding was that Ceph was on the cluster network?
We are a monitoring company so we receive thousands of signals each hour and the downtime is a major issue for us if we had a failover incident on ZFS HA, maybe I should consider this to resolve the current issue prior to building a ssd only ceph pool.
How can I confirm and change ceph/public network? My understanding is that they share the same NIC's?
We are a monitoring company so we receive thousands of signals each hour and the downtime is a major issue for us if we had a failover incident on ZFS HA, maybe I should consider this to resolve the current issue prior to building a ssd only ceph pool.
How can I confirm and change ceph/public network? My understanding is that they share the same NIC's?
")