I am writing this to express my deep frustration regarding the pve-qemu-kvm 10.2.1-1 update. I manage a massive infrastructure of over 1,200 nodes, and this untested update has caused significant distress across my entire operation.
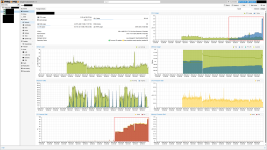
I have spent the last two nights without sleep, monitoring spikes in IO Delay, CPU, and RAM usage that appeared immediately after this update. It is honestly disappointing to see a core package released to the Trixie repository with such a glaring regression that impacts real-world performance, not just "graphs."
After extensive testing and stress, I confirmed that downgrading to 10.1.2-7 resolved the issue on my clusters. In an enterprise-grade environment of this scale, we rely on the stability of these updates. Having to manually intervene across such a large fleet due to an avoidable bug is unacceptable.
I hope this serves as a wake-up call for more rigorous QA before pushing updates that handle core hypervisor functions. I am still recovering from the stress and lack of sleep this has caused.
Looking forward to a stable, properly tested fix soon.
Sorry, I'm out. All of the above is on you. Who told you to implement the "test" repository in "an enterprise-grade environment of this scale".
It is not published in either pve-no-subscription or pve-enterprise repositories.
I don't dispute you experienced an issue - however remember one workaround was clearly documented by @uzumo (thanks that user!) and further diagnostic suggestions were made by @fiona
I mean, the results of which for MY environment were supplied - subsequent to which @fiona had confirmed replicating an issue. Its being looked at.
You might - just might have an argument had this reached a production repo but its a test repo. To be clear, I had my own issues with a bug report recently but you cannot blame a TEST repo for your production issues.
Happy Proxmox in future.


")