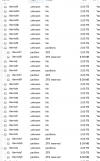
I have a D3284 with 84 HDD and my primary NODE1 with 8 SSD already named.
16 RaidZ3 pools with 84 disks. This is because each Raidz3 pool requires at least 5 disks, so 84 disks can be divided into 16 pools of 5 disks each with 4 remaining for other use.
How can this naming process be improved?
No matter if Fdisk and deleted pools... when I start creating NEW pools the disk naming process jumps to different disks after like 8 pools are created.
Different IDs too so I'm at a loss. When I reboot my Node 1 first and then start my Direct Attached Storage, the HDD naming process goes back to normal. Then I start creating pools but only after Fdisk, Delete Pools, reboot, and check the status of pools then I begin. I thought the ordering process does not matter with storage pools
What I want to know is if the naming process starts with SDA all the way to SDZ?
Since the first 8 SSD disks were already named SDA to SDH
should I start the new pool naming process with the next one after SDH like - SDI, SDJ, SDK, SDL, SDM, all the way until SDZ then start with SDAA, SDAB etc?
I'm thinking this is why this is happening to me. Will let everyone know if continuing to SDZ pays off.
16 RaidZ3 pools with 84 disks. This is because each Raidz3 pool requires at least 5 disks, so 84 disks can be divided into 16 pools of 5 disks each with 4 remaining for other use.
How can this naming process be improved?
No matter if Fdisk and deleted pools... when I start creating NEW pools the disk naming process jumps to different disks after like 8 pools are created.
Different IDs too so I'm at a loss. When I reboot my Node 1 first and then start my Direct Attached Storage, the HDD naming process goes back to normal. Then I start creating pools but only after Fdisk, Delete Pools, reboot, and check the status of pools then I begin. I thought the ordering process does not matter with storage pools
What I want to know is if the naming process starts with SDA all the way to SDZ?
Since the first 8 SSD disks were already named SDA to SDH
should I start the new pool naming process with the next one after SDH like - SDI, SDJ, SDK, SDL, SDM, all the way until SDZ then start with SDAA, SDAB etc?
I'm thinking this is why this is happening to me. Will let everyone know if continuing to SDZ pays off.
Attachments

Last edited: