On my 4-Node Cluster with Ceph I shut down one system to make some BIOS changes.
The issue is the cluster came to a complete stop while doing this.
What I checked beforehand on the shutdown node:
The issue is the cluster came to a complete stop while doing this.
What I checked beforehand on the shutdown node:
- No HA rules are applied to any of the VMs, LXCs
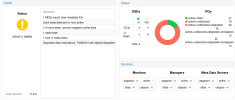
- All are on Ceph Storage
- No Backup is running on that Node




")