Hi all,
I’m new to the forums and posting here as I’m facing a major issue and could really use some assistance.
P.S. I’m a network engineer rather than a systems administrator, so please bear with me if I miss something that may seem simple from a hypervisor perspective.
I’m currently running a MikroTik CHR (RouterOS 7.20.8 → 7.23beta2) VM on Proxmox and experiencing a persistent issue where latency gradually increases over time, eventually leading to traffic stopping entirely until the VM is rebooted.
I’ve been in contact with MikroTik support, and they indicated there were known virtio-net driver issues in CHR versions prior to 7.23. Based on their recommendation, I upgraded to 7.23beta2.
Since the upgrade, the latency creep issue appears to be resolved. However, after a few hours, the CHR still stalls. A reboot of the CHR restores normal operation.
From my observations, it seems that traffic to and from the CHR stalls, rather than the CHR itself. Scripts and internal processes continue running during the issue, which has allowed me to automate reboots and generate support files for MikroTik.
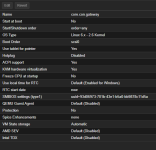
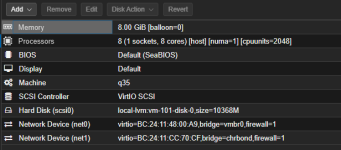
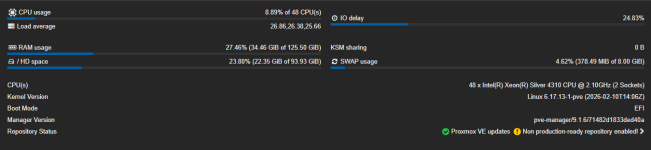
Please see my Proxmox resource allocation and configuration for this VM (attached/screenshots). Any assistance or suggestions would be greatly appreciated.
This issue started about 3 weeks ago maybe even 4. Im using PVE 9.1.6
I’m new to the forums and posting here as I’m facing a major issue and could really use some assistance.
P.S. I’m a network engineer rather than a systems administrator, so please bear with me if I miss something that may seem simple from a hypervisor perspective.
I’m currently running a MikroTik CHR (RouterOS 7.20.8 → 7.23beta2) VM on Proxmox and experiencing a persistent issue where latency gradually increases over time, eventually leading to traffic stopping entirely until the VM is rebooted.
I’ve been in contact with MikroTik support, and they indicated there were known virtio-net driver issues in CHR versions prior to 7.23. Based on their recommendation, I upgraded to 7.23beta2.
Since the upgrade, the latency creep issue appears to be resolved. However, after a few hours, the CHR still stalls. A reboot of the CHR restores normal operation.
From my observations, it seems that traffic to and from the CHR stalls, rather than the CHR itself. Scripts and internal processes continue running during the issue, which has allowed me to automate reboots and generate support files for MikroTik.
Please see my Proxmox resource allocation and configuration for this VM (attached/screenshots). Any assistance or suggestions would be greatly appreciated.
This issue started about 3 weeks ago maybe even 4. Im using PVE 9.1.6
Attachments
Last edited:


