Latest activity
-
OOnslow reacted to portedaix's post in the thread Backup speed regression: 2h20m → 8h39m after PVE 8→9 / QEMU 9.2→10.1 / Ceph 18→19 upgrade with
 Like.
Hi, That was a beginner mistake. Real root cause (found 2026-05-06): discard=on was missing from scsi1 in the QEMU config. For over a year, every ext4 TRIM was silently dropped by QEMU and never propagated down to Ceph → 2.7 TiB of orphaned RBD...
Like.
Hi, That was a beginner mistake. Real root cause (found 2026-05-06): discard=on was missing from scsi1 in the QEMU config. For over a year, every ext4 TRIM was silently dropped by QEMU and never propagated down to Ceph → 2.7 TiB of orphaned RBD... -
OOnslow replied to the thread Error with upgrading from Proxmox 8 to 9.Hi, @mickyface Could it be one more case of the situation solved in this thread? https://forum.proxmox.com/threads/pbs-4-upgrade-on-a-dell-nx3230-doesnt-fully-boot.183192/post-851045
-
JJohannes S replied to the thread Use Disk PassThrough or Raid-0 for PVE with Ceph (Testsystem).It depends on your usecase. If you want to have still a working cluster if two nodes get down (due to maintenance or failure) you will need more than three nodes for the reasons Udo explained in his writeup. But if you are fine with just being...
-
JJohannes S reacted to Martin.B.'s post in the thread Use Disk PassThrough or Raid-0 for PVE with Ceph (Testsystem) with Like.
It will be to see the difference of using ceph on lokal storage vs. PVE nodes without local storage and some kind of remote storage. If any of this will be used in future production environment there will not be much "load" on it. Not CPU nor...
-
JJohannes S reacted to alexskysilk's post in the thread Use Disk PassThrough or Raid-0 for PVE with Ceph (Testsystem) with Like.
This is a major point. using ceph on this sort of POC will not teach you how to actually use ceph in production since you wont be able to actually put the type of load on it that would be meaningful. Is your intention to use this knowledge to put...
-
JJohannes S reacted to Martin.B.'s post in the thread Use Disk PassThrough or Raid-0 for PVE with Ceph (Testsystem) with Like.
Thanks for your fast answers, looks like i will go this way and only use 2 of the hardware machines and build the ceph cluster virtual. The machines do only have 32GB RAM and an older 6 core CPU, so maybe using 2 hardware machines will be better...
-
JJohannes S reacted to aaron's post in the thread Use Disk PassThrough or Raid-0 for PVE with Ceph (Testsystem) with Like.
This is what we use for many internal tests, and also in the hands-on labs for our trainings. Good for functionality and behavior tests as long as performance is not a factor!
-
JJohannes S reacted to UdoB's post in the thread Use Disk PassThrough or Raid-0 for PVE with Ceph (Testsystem) with Like.
Sure! For teaching/learning/debugging this works great. Example: in my Homelab I have one specific cluster member with 64 GiB Ram and 2 TB local storage for VMs. I was able to create six virtual PVE nodes with 8 GiB Ram each, construct a...
-
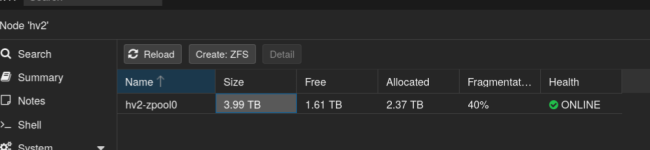
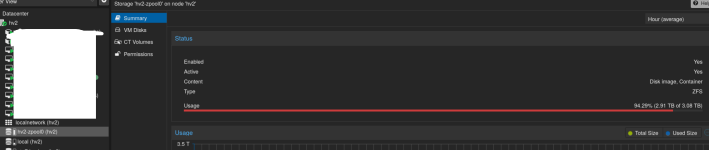
JThese basically show similar things to zpool status and zfs list. RAIDZ has padding overhead and the GUI also mixes different units (TB vs TiB) and that's where the discrepancy comes from. This was talked about here: -...
-
Mmosespray posted the thread community.proxmox.proxmox_kvm not setting VLAN Tag on update in Proxmox VE: Installation and configuration.Hello, I am trying to fully automate my disaster recovery solution for my Proxmox homelab. I am using Proxmox Virtual Environment 9.1.9 and ansible [core 2.20.5]. I am also using the latest community.proxmox.promox library. I have a set of...
-
-
Kknewman replied to the thread Confused About my ZFS Storage.Thanks for the quick reply! The links are very helpful.
-
KThese basically show similar things to zpool status and zfs list. RAIDZ has padding overhead and the GUI also mixes different units (TB vs TiB) and that's where the discrepancy comes from. This was talked about here: -...
-
Kknewman posted the thread Confused About my ZFS Storage in Proxmox VE: Installation and configuration.Hello, I'm hoping someone more knowledgeable than me can help me understand how much space I actually have left on my Proxmox ZFS pool. If I do a zpool list -v I get an ouput saying my pool is 3.62T in size with 2.16T allocated and 1.47T free...
-
-
 powersupport replied to the thread Unable to remove a snapshot.Hi, It looks like the tape-restored snapshot may still have some locked or protected metadata. You may try: Running datastore verify Running garbage collection Checking for active tasks/locks Restarting proxmox-backup-proxy If normal removal...
powersupport replied to the thread Unable to remove a snapshot.Hi, It looks like the tape-restored snapshot may still have some locked or protected metadata. You may try: Running datastore verify Running garbage collection Checking for active tasks/locks Restarting proxmox-backup-proxy If normal removal... -
OOk, I now succeeded: as a last step, one does indeed have to repair the partition table. Here's a short writup on how I finally did it to shrink a VM hard drive from 120G (14% used by Ubuntu server 24.04 LTS) to 56G on a ZFS volume: First of...
-
OOnslow replied to the thread [Proxmox Backup] Backups fail to lock file.@hac3ru , I think you are right.
-
 Falk R. reacted to vmwombat's post in the thread [SOLVED] Installation aktuelle PVE9 ISO auf PRIMERGY RX2540 M8 mit PDUAL CP300 bleibt bei 99% hängen with Like.
Danke Falk! So habe ich es nun auch gemacht. Alles andere ist mir zu heikel.
Falk R. reacted to vmwombat's post in the thread [SOLVED] Installation aktuelle PVE9 ISO auf PRIMERGY RX2540 M8 mit PDUAL CP300 bleibt bei 99% hängen with Like.
Danke Falk! So habe ich es nun auch gemacht. Alles andere ist mir zu heikel. -
Falk R. reacted to Johannes S's post in the thread Yet another "ZFS on HW-RAID" Thread (with benchmarks) with Like.
In regard to the discussion: I remember that @Falk R. mentioned several times in the German forum that using ZFS on HW RAID is ok if (and only if): You know what you are doing (which imho doesn't hold true for people calling others "dogmatic"...
-
Kkur1j replied to the thread Proxmox 9.1.7 RTX 6000 Pro drops off PCI bus.Ironically...happened quicker than I thought...this particular system seems to see the issue more than our other systems. From this morning all cards were being detected 0000:3d:00.0 - not assigned; detected 0000:3e:00.0 - not assigned...
-
CcluelessUser posted the thread Intel Arc Pro B50 SR-VIO not working in Proxmox VE: Installation and configuration.Hoping a member of the community can assist me with this... I would like to split the B50 into two cards so I can use them in two different VMs. However, I haven't been able to get it working and I'm bit lost. Thank you in advance! Config &...