Latest activity
-
BBR6 replied to the thread GMKTEC K12 | Ryzen 7 H 255 | Problem with IGPU.Just updating I got igpu passthru working also Bios 2.03, vbios 2.02 that i extracted myself Args from beisser’s post thanks
-
YYaZoal replied to the thread Corosync - Cluster retransmit issues | pmxcfs / corosync synchronization problems | Proxmox cluster 3 nodes.Please also check /etc/corosync/corosync.conf . Does the addresses correct as the one you wanted? compare the nodes. If possible please share from 2 nodes on this cluster: ~# pvecm status ~# cat /etc/pve/corosync.conf Also collect and share...
-
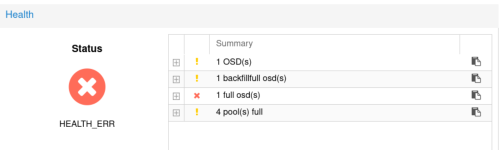
Bbluewolf42 posted the thread Resolving "full osd(s)", "backfillfull osd(s)" and "pool(s) full" in Proxmox VE: Installation and configuration.Yesterday I was greeted with numerous unreachable services stemming from a Ceph health error on our VM cluster due to "1 full osd(s)" and "1 backfillfull osd(s)" resulting in "4 pool(s) full" and solved it. This was the ceph status panel: As a...
-
-
Pplurgi95 posted the thread Löschen von VM-Snapshots nach Speicher Erweiterung in Proxmox VE (Deutsch/German).Hallo, mir ist aufgefallen Dass ich nach dem Hinzufügen von Speicherplatz bei einer VM den Erstellten Snapshot nicht mehr löschen kann wenn diese vor dem Hinzufügen von Speicherplatz schon bestand. Hat hier jemand erfahrungen wie man die...
-
Ppsalkiewicz replied to the thread [SOLVED] Fixing broken cluster.PVE blocks changes to cluster file system: 1. Stop the cluster services on the node you're changing (Server5) systemctl stop pve-cluster systemctl stop corosync 2. Mount pmxcfs in local mode (bypasses cluster lock) pmxcfs -l 3. Edit...
-
Pplurgi95 replied to the thread [SOLVED] PBS-Datastore Monitor.Wir haben für Moitoring einen Dienst der Pro Monitoring Slot geld kostet, (Ja es gibt NFR Lizenzen dazu haben wir aber nicht Genügend Slots verkauft) und in diesem sind auch die Einstellungsmöglichkeiten Begrenzt. Daher machen wir dass unter...
-
Kkd-infradijon replied to the thread Corosync - Cluster retransmit issues | pmxcfs / corosync synchronization problems | Proxmox cluster 3 nodes.I proceeded to the vimdiff between the différent reports, no differences about the version of the dependences. I changed the migration network too, thk yu for the advice. Regards, IDEZ Ugo
-
 dcsapak replied to the thread Two GPU and their assigment to /dev/dri/renderD....an alternative would be to use '/dev/dri/by-path' which encodes the pciid and that should be more stable? (i hope at least)
dcsapak replied to the thread Two GPU and their assigment to /dev/dri/renderD....an alternative would be to use '/dev/dri/by-path' which encodes the pciid and that should be more stable? (i hope at least) -
 fschauer replied to the thread Two GPU and their assigment to /dev/dri/renderD....Set up udev rules on the host to map the devices to persistently named device nodes. Then pass these consistently named device nodes to the containers.
fschauer replied to the thread Two GPU and their assigment to /dev/dri/renderD....Set up udev rules on the host to map the devices to persistently named device nodes. Then pass these consistently named device nodes to the containers. -
 fiona replied to the thread Starting VM 102 failed: no such logical volume pve/vm-102-disk-0.Hi, should you have enabled HA for the guest, note that having shared storage is a prerequisite for enabling HA and using HA can lead to such issues when there are local disks...
fiona replied to the thread Starting VM 102 failed: no such logical volume pve/vm-102-disk-0.Hi, should you have enabled HA for the guest, note that having shared storage is a prerequisite for enabling HA and using HA can lead to such issues when there are local disks... -
YYaZoal replied to the thread Corosync - Cluster retransmit issues | pmxcfs / corosync synchronization problems | Proxmox cluster 3 nodes.Hello IDES, Alright, also If you haven't already, double check that the MTU settings are consistent between the nodes in the cluster. I usually find it easier to verify the configuration by generating a system report from each node using the...
-
Ppixel24 posted the thread After a power outage, pve/data cannot be activated or repaired in Proxmox VE: Installation and configuration.Hi everyone, I still have a very old PVE 7.4-19 setup here with Thin-LVM on LSI hardware RAID. After a power outage, pve/data can no longer be activated. The volume group is 100% allocated, but the "data" inside it (VM disks & snapshots)...
-
fiona replied to the thread TASK ERROR: activating LV 'pve/data' failed: Check of pool pve/data failed (status:64). Manual repair required!.Did you already run a health check for the device with e.g. smartctl? What was the output of that command? I'd be a bit surprised if it did anything to the LVM, since the targeted /dev/sda contains partitions, your PV is on /dev/sda3 and does...
-
Aadrianovf replied to the thread VM Comes back alive? (after deleting).Hello, I just realized wipefs is not the best solution, anytime I delete a VM, it raises the CPU of the storage too much, which is not ideal it can disrupt the storage in production. Is there any other ways to tackle this ghost VM issue?
-
JJohannes S reacted to Alwin Antreich's post in the thread Problem mit Hinzufügen von SSD-Speicher in Resource Pool with
 Like.
So weit würde ich nicht gehen. :) Je nach Storage wird diese Name auch anderweitig verwendet, zB. zfs pool name. Und wenn bereits VM/CT drauf liegen, dann haben die auch den alten Storage Namen für ihre Disks eingetragen. Die storage.cfg zu...
Like.
So weit würde ich nicht gehen. :) Je nach Storage wird diese Name auch anderweitig verwendet, zB. zfs pool name. Und wenn bereits VM/CT drauf liegen, dann haben die auch den alten Storage Namen für ihre Disks eingetragen. Die storage.cfg zu... -
Kkd-infradijon replied to the thread Corosync - Cluster retransmit issues | pmxcfs / corosync synchronization problems | Proxmox cluster 3 nodes.Hello YaZoal, Thank you for your help. The MTU is the same on each interfaces of each node : ip link | grep mtu 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 2: nic1...
-
Kkd-infradijon replied to the thread Corosync - Cluster retransmit issues | pmxcfs / corosync synchronization problems | Proxmox cluster 3 nodes.Hello Abamalu, Thank you for your help. We have no drops or errors on the NIC2 interface: ip -s link show nic2 3: nic2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq master vmbr0 state UP mode DEFAULT group default qlen 1000...
-
fiona replied to the thread Failed backup - unable to activate storage.Hi, are you using the same network for PBS and NFS traffic? How does the load look like when the issue occurs? It might transient issues where the check whether the NFS mount point is reachable times out.
-
AAndrii.B replied to the thread [SOLVED] IO-Trouble wit zfs-mirror on pve7.2 (5.15.39-1-pve) - BUG: soft lockup inside VMs.There is a similar and newer topic here. This problem occurs when creating a backup with big disk space. It depends with ballooning. I'm still investigating how to resolve it but it seems to me, it's necessary to disable ballooning on VM.
-
66equj5 replied to the thread [TUTORIAL] PoC 2 Node HA Cluster with Shared iSCSI GFS2.This sounds interesting: https://www.starwindsoftware.com/proxmox-san-integration-services Tested here: https://www.virtualizationhowto.com/2026/04/i-almost-gave-up-on-proxmox-iscsi-storage-in-my-home-lab-then-this-worked/