Latest activity
-
Aalexskysilk replied to the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster?.K=6,M=2 results in 6 data strips per 8 total. 6/8=0.75 in replication you have 1 data strips per 3 total. 1/3=0.33 its not exactly the "same" availability because survivability in a replication group is much higher; you need one living osd per...
-
 weehooey-cd replied to the thread HA replication.Hello wondimu, May we know more about the Disks? Or Perhaps get a PVE report? It is possible that only some of the Disk are stored on media that allows replication. Report can be generated by going to DataCenter > Node > Subscription > Click...
weehooey-cd replied to the thread HA replication.Hello wondimu, May we know more about the Disks? Or Perhaps get a PVE report? It is possible that only some of the Disk are stored on media that allows replication. Report can be generated by going to DataCenter > Node > Subscription > Click... -
 UdoB reacted to Johannes S's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with
UdoB reacted to Johannes S's post in the thread Pardon my less-than-intelligent question, but is there a way to install Proxmox on a Ceph cluster? with Like.
Although they were about replicated pools (so no ec) following reads might serve as a hint why (outside of experiments/lab setups) it's not a good idea to go against the recommendations...
Like.
Although they were about replicated pools (so no ec) following reads might serve as a hint why (outside of experiments/lab setups) it's not a good idea to go against the recommendations... -
NNexces replied to the thread Is a 3-node Full Mesh Setup For Ceph and Corosync Good or Bad.@x509 corosync is on 1G "private" link no redundancy for 25G - single node failure is accepted as datacenter in which those servers are has 24h service and spare parts - faulty node will be up in matter of minutes / hours there is total of 70 VMs...
-
Gglarsen reacted to IsThisThingOn's post in the thread Storage for small clusters, any good solutions? with Like.
Take this with a huge grain of salt. I don't know you or your customers :) IMHO you probably don't need HA. Redudant PSU and local storage is more than enough. And your next part is a good explanation why. That is not automatically real HA...
-
WI see that we have replication enabled between the two nodes, but one of the VMs is only replicating half of its disks. Is there a solution to fix this?”
-
Rrodfranck posted the thread Ubuntu 24.04 cloud-init fails on LVM (Fibre Channel) storage in Proxmox 9 when provisioned via Terraform in Proxmox VE: Installation and configuration.Hello everyone, I’m currently working on an automation project to provision virtual machines in Proxmox 9 using Terraform (BPG provider) together with cloud-init. The virtual machines are based on Ubuntu 24.04 cloud images. The provisioning...
-
-
FFelix. reacted to jsterr's post in the thread Ceph 20.2 Tentacle Release Available as test preview and Ceph 18.2 Reef soon to be fully EOL with Like.
Seems like tentacle has landed in no-subscription now (noticed it today) :-)
-
FFelix. reacted to sbarmen's post in the thread Ceph 20.2 Tentacle Release Available as test preview and Ceph 18.2 Reef soon to be fully EOL with Like.
Just upgraded myself. Went just fine no issues. 3 OSDs. I got some interesting data after upgrading: Ceph Squid → Tentacle Upgrade Benchmark Summary Cluster: 3-node Proxmox (Intel NUC14, NVMe) Pool: ceph-vms (replicated, size 2 / min_size 2)...
-
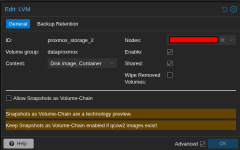
Ddork replied to the thread Snapshot causes VM to become unresponsive..Hi Fiona, No, i did not use snapshot-as-volume-chain, i changed the clustersize to 1M instead of 64k, i would like to share more information how to implement it (installation scripts, etc) if you can implement this in the next version, etc..
-
Mmanuelkamp replied to the thread Proxmox 9.1.5 breaks LXC mount points?.is it fixed with 6.1.2? I downgraded to 6.0.18 and never did any update since then to prevent issues with samba mountpoints here
-
JJohannes S replied to the thread LVM on shared storage.You can use lvm/thick (NOT lvm/thin) on ISCSI/NVMEoE/FC-attached SAN-/NAS-Storages.
-
Hhumdrum replied to the thread ESXi Import Wizard: create storage failed: failed to spawn fuse mount...?.Apologies for Necro'ing this thread, but it is the first hit on google. and its the one I kept stumbling back to when searching the error "create storage failed: failed to spawn fuse mount, process exited with status 65280 (500)" when looking...
-
Eebaggs replied to the thread Storage for small clusters, any good solutions?.My company has been using Proxmox for a while now and have deployed in a variety of uses and I can confirm that Blockbridge has definitely been the most straight forward way to address the problems you've mentioned. While Proxmox doesn't official...
-
JJohannes S replied to the thread Abschalten von "You do not have a valid subscription for this server ...................".Laut Aussage eines Proxmox Entwicklers hat man darüber schon nachgedacht und ist zum Schluss gekommen, dass das konterproduktiv ist: - Es gab schon früher mal eine Möglichkeit zu spenden, die dabei entstehenden Einnahmen (bzw. deren Mangel)...
-
JJohannes S reacted to proxuser77's post in the thread Abschalten von "You do not have a valid subscription for this server ..................." with Like.
Ja, oder man zahlt gar nichts und klickt diese Meldung einfach weg. Oder man googelt, wie man sie los wird, falls einem dieses Ding tatsächlich schlaflose Nächte bereitet. ;) Bezüglich der Unterstützung mit „Peanuts” sieht es laut offiziellen...
-
JThat will work if you have a quorum machine. We used DRBD+LVM in active/active heavily with XEN before we switched to PVE over 10 years ago, but we used clvm with XEN and in the beginning with PVE, but it was replaced with PVE internal logic to...
-
JJohannes S reacted to aL1aL7's post in the thread Veeam & Proxmox bei Shared Storage via FC with Like.
Die Backups mit dem PBS sind soweit schon "application aware", wenn der qemu-guest-agent auf den VM's installiert ist, weil ja - wie Du schon geschrieben hast - ein freeze mit dem qemu-agent ausgeführt wird und somit in der "Luft" befindliche...
-
Ssidoni posted the thread Upgrade from pve8to9: "old machine version" in Proxmox VE: Installation and configuration.Hi guys, I would like to upgrade my PVE v.8 to v.9. pve8to9 --full returns 2 warnings: Could you please tell me what should I do to get a smooth upgrade? Thanks for your kind help.
-
Gglarsen replied to the thread Storage for small clusters, any good solutions?.We are a blockbridge customer for our cloud (2yrs, 2 zen4-48 clusters) and are working to migrate some larger customers onto their own blockbridges. Can't say enough about their storage knowledge and support. They are one of my favorite vendors...