I recently upgraded my CPU (AMD Ryzen 5 2600X to Ryzen 5 5600G) and at the same time did a BIOS update. Unfortunately something apparently happened as I'm no longer able to run Proxmox.
The machine can start in recovery mode with SSH and so far so good, no errors on zpool or anywhere else as far as I can tell. But as soon as I 'exit' recovery mode something causes the zpool to be suspended according to:
And after that no more terminal commands are accepted. If I do a normal boot I have a brief time to login before the terminal is unresponsive of commands. When looking at 'top' after logging in it appears as the errors start showing up right after KVM process has started.
Hardware
CPU: AMD Ryzen 5 5600G
MB: ASUS Prime B450M-A
SSD: Samsung SSD 870 EVO 500GB (2 in ZFS mirror mode.)
What I have tried:
- Different BIOS settings; SVM, IOMMU, SR-IOV, UEFI/Legacy boot, etc.
- Replaced the SATA cables.
- Changed the SATA ports.
- Downgraded BIOS (I couldn't however downgrade to the version I had previously as there was something wrong with that specific version 'Not a valid BIOS file' or along those lines. I did however try the next version after my initial BIOS. Same issue whatever version is installed.)
- zpool scrub
- smartctl -t short on /dev/sda and /dev/sdb
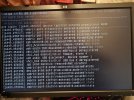
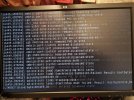
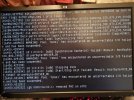
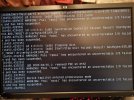
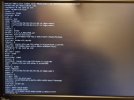
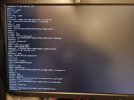
What I'm looking into now is an error message that shows up right before some zio logs in that wall of text passing by (see attached photos).
Without knowing to much about these messages my first thought is that it might be a disk error. It just seems a bit unlikely that the disk error would occur at the same time as the BIOS update? Also I had some hopes that mirroring and zfs would help against errors like this, but I'm most likely missing some knowledge in this area.
Any suggestions what to do? I'm not very well familiar with nix command line disk management or ZFS so any recommendations would be appreciated. Let me know if there is any additional information that would help out when solving this.
The machine can start in recovery mode with SSH and so far so good, no errors on zpool or anywhere else as far as I can tell. But as soon as I 'exit' recovery mode something causes the zpool to be suspended according to:
WARNING: Pool 'rpool' has encountered an uncorrectable I/O failure and has been suspended.And after that no more terminal commands are accepted. If I do a normal boot I have a brief time to login before the terminal is unresponsive of commands. When looking at 'top' after logging in it appears as the errors start showing up right after KVM process has started.
Hardware
CPU: AMD Ryzen 5 5600G
MB: ASUS Prime B450M-A
SSD: Samsung SSD 870 EVO 500GB (2 in ZFS mirror mode.)
What I have tried:
- Different BIOS settings; SVM, IOMMU, SR-IOV, UEFI/Legacy boot, etc.
- Replaced the SATA cables.
- Changed the SATA ports.
- Downgraded BIOS (I couldn't however downgrade to the version I had previously as there was something wrong with that specific version 'Not a valid BIOS file' or along those lines. I did however try the next version after my initial BIOS. Same issue whatever version is installed.)
- zpool scrub
- smartctl -t short on /dev/sda and /dev/sdb
proxmox-ve: 6.4-1 (running kernel: 5.4.203-1-pve)
pve-manager: 6.4-15 (running version: 6.4-15/af7986e6)
pve-kernel-5.4: 6.4-20
pve-kernel-helper: 6.4-20
pve-kernel-5.4.203-1-pve: 5.4.203-1
pve-kernel-5.4.128-1-pve: 5.4.128-2
pve-kernel-5.4.124-1-pve: 5.4.124-2
pve-kernel-5.4.119-1-pve: 5.4.119-1
pve-kernel-5.4.106-1-pve: 5.4.106-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.1.5-pve2~bpo10+1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: 0.8.35+pve1
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.22-pve2~bpo10+1
libproxmox-acme-perl: 1.1.0
libproxmox-backup-qemu0: 1.1.0-1
libpve-access-control: 6.4-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.4-5
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.2-5
libpve-storage-perl: 6.4-1
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.1.14-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.6-2
pve-cluster: 6.4-1
pve-container: 3.3-6
pve-docs: 6.4-2
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-4
pve-firmware: 3.3-2
pve-ha-manager: 3.1-1
pve-i18n: 2.3-1
pve-qemu-kvm: 5.2.0-8
pve-xtermjs: 4.7.0-3
qemu-server: 6.4-2
smartmontools: 7.2-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.7-pve1
pve-manager: 6.4-15 (running version: 6.4-15/af7986e6)
pve-kernel-5.4: 6.4-20
pve-kernel-helper: 6.4-20
pve-kernel-5.4.203-1-pve: 5.4.203-1
pve-kernel-5.4.128-1-pve: 5.4.128-2
pve-kernel-5.4.124-1-pve: 5.4.124-2
pve-kernel-5.4.119-1-pve: 5.4.119-1
pve-kernel-5.4.106-1-pve: 5.4.106-1
pve-kernel-5.4.73-1-pve: 5.4.73-1
ceph-fuse: 12.2.11+dfsg1-2.1+b1
corosync: 3.1.5-pve2~bpo10+1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: 0.8.35+pve1
ksm-control-daemon: 1.3-1
libjs-extjs: 6.0.1-10
libknet1: 1.22-pve2~bpo10+1
libproxmox-acme-perl: 1.1.0
libproxmox-backup-qemu0: 1.1.0-1
libpve-access-control: 6.4-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.4-5
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.2-5
libpve-storage-perl: 6.4-1
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.1.14-1
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.6-2
pve-cluster: 6.4-1
pve-container: 3.3-6
pve-docs: 6.4-2
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-4
pve-firmware: 3.3-2
pve-ha-manager: 3.1-1
pve-i18n: 2.3-1
pve-qemu-kvm: 5.2.0-8
pve-xtermjs: 4.7.0-3
qemu-server: 6.4-2
smartmontools: 7.2-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.7-pve1
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 465.8G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 512M 0 part
└─sda3 8:3 0 465.3G 0 part
sdb 8:16 0 465.8G 0 disk
├─sdb1 8:17 0 1007K 0 part
├─sdb2 8:18 0 512M 0 part
└─sdb3 8:19 0 465.3G 0 part
zd0 230:0 0 4M 0 disk
zd16 230:16 0 1.5G 0 disk
zd32 230:32 0 32G 0 disk
├─zd32p1 230:33 0 50M 0 part
├─zd32p2 230:34 0 31.5G 0 part
└─zd32p3 230:35 0 505M 0 part
zd48 230:48 0 100G 0 disk
├─zd48p1 230:49 0 1M 0 part
├─zd48p2 230:50 0 1G 0 part
└─zd48p3 230:51 0 99G 0 part
zd64 230:64 0 8.5G 0 disk
zd80 230:80 0 32G 0 disk
├─zd80p1 230:81 0 50M 0 part
├─zd80p2 230:82 0 31.5G 0 part
└─zd80p3 230:83 0 505M 0 part
zd96 230:96 0 32G 0 disk
├─zd96p1 230:97 0 50M 0 part
├─zd96p2 230:98 0 31.5G 0 part
└─zd96p3 230:99 0 505M 0 part
zd112 230:112 0 32G 0 disk
├─zd112p1 230:113 0 50M 0 part
├─zd112p2 230:114 0 31.5G 0 part
└─zd112p3 230:115 0 505M 0 part
zd128 230:128 0 32G 0 disk
├─zd128p1 230:129 0 1007K 0 part
├─zd128p2 230:130 0 512M 0 part
└─zd128p3 230:131 0 31.5G 0 part
zd144 230:144 0 20G 0 disk
├─zd144p1 230:145 0 32M 0 part
├─zd144p2 230:146 0 24M 0 part
├─zd144p3 230:147 0 256M 0 part
├─zd144p4 230:148 0 24M 0 part
├─zd144p5 230:149 0 256M 0 part
├─zd144p6 230:150 0 8M 0 part
├─zd144p7 230:151 0 96M 0 part
└─zd144p8 230:152 0 19.3G 0 part
zd160 230:160 0 4G 0 disk
├─zd160p1 230:161 0 4G 0 part
├─zd160p5 230:165 0 3.8G 0 part
└─zd160p6 230:166 0 205M 0 part
sda 8:0 0 465.8G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 512M 0 part
└─sda3 8:3 0 465.3G 0 part
sdb 8:16 0 465.8G 0 disk
├─sdb1 8:17 0 1007K 0 part
├─sdb2 8:18 0 512M 0 part
└─sdb3 8:19 0 465.3G 0 part
zd0 230:0 0 4M 0 disk
zd16 230:16 0 1.5G 0 disk
zd32 230:32 0 32G 0 disk
├─zd32p1 230:33 0 50M 0 part
├─zd32p2 230:34 0 31.5G 0 part
└─zd32p3 230:35 0 505M 0 part
zd48 230:48 0 100G 0 disk
├─zd48p1 230:49 0 1M 0 part
├─zd48p2 230:50 0 1G 0 part
└─zd48p3 230:51 0 99G 0 part
zd64 230:64 0 8.5G 0 disk
zd80 230:80 0 32G 0 disk
├─zd80p1 230:81 0 50M 0 part
├─zd80p2 230:82 0 31.5G 0 part
└─zd80p3 230:83 0 505M 0 part
zd96 230:96 0 32G 0 disk
├─zd96p1 230:97 0 50M 0 part
├─zd96p2 230:98 0 31.5G 0 part
└─zd96p3 230:99 0 505M 0 part
zd112 230:112 0 32G 0 disk
├─zd112p1 230:113 0 50M 0 part
├─zd112p2 230:114 0 31.5G 0 part
└─zd112p3 230:115 0 505M 0 part
zd128 230:128 0 32G 0 disk
├─zd128p1 230:129 0 1007K 0 part
├─zd128p2 230:130 0 512M 0 part
└─zd128p3 230:131 0 31.5G 0 part
zd144 230:144 0 20G 0 disk
├─zd144p1 230:145 0 32M 0 part
├─zd144p2 230:146 0 24M 0 part
├─zd144p3 230:147 0 256M 0 part
├─zd144p4 230:148 0 24M 0 part
├─zd144p5 230:149 0 256M 0 part
├─zd144p6 230:150 0 8M 0 part
├─zd144p7 230:151 0 96M 0 part
└─zd144p8 230:152 0 19.3G 0 part
zd160 230:160 0 4G 0 disk
├─zd160p1 230:161 0 4G 0 part
├─zd160p5 230:165 0 3.8G 0 part
└─zd160p6 230:166 0 205M 0 part
pool: rpool
state: ONLINE
status: Some supported features are not enabled on the pool. The pool can
still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(5) for details.
scan: scrub repaired 0B in 00:07:47 with 0 errors on Tue Dec 6 04:00:28 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ata-Samsung_SSD_870_EVO_500GB_S62BNJ0NC07966D-part3 ONLINE 0 0 0
ata-Samsung_SSD_870_EVO_500GB_S62BNJ0NC07961V-part3 ONLINE 0 0 0
errors: No known data errors
state: ONLINE
status: Some supported features are not enabled on the pool. The pool can
still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(5) for details.
scan: scrub repaired 0B in 00:07:47 with 0 errors on Tue Dec 6 04:00:28 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ata-Samsung_SSD_870_EVO_500GB_S62BNJ0NC07966D-part3 ONLINE 0 0 0
ata-Samsung_SSD_870_EVO_500GB_S62BNJ0NC07961V-part3 ONLINE 0 0 0
errors: No known data errors
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
9 Power_On_Hours 0x0032 097 097 000 Old_age Always - 14517
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 88
177 Wear_Leveling_Count 0x0013 049 049 000 Pre-fail Always - 1216
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0032 078 036 000 Old_age Always - 22
195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always - 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
235 Unknown_Attribute 0x0012 099 099 000 Old_age Always - 40
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 272102793057
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 14504 -
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
9 Power_On_Hours 0x0032 097 097 000 Old_age Always - 14517
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 88
177 Wear_Leveling_Count 0x0013 049 049 000 Pre-fail Always - 1216
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0032 078 036 000 Old_age Always - 22
195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always - 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
235 Unknown_Attribute 0x0012 099 099 000 Old_age Always - 40
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 272102793057
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 14504 -
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
9 Power_On_Hours 0x0032 097 097 000 Old_age Always - 14517
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 87
177 Wear_Leveling_Count 0x0013 053 053 000 Pre-fail Always - 1121
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0032 078 036 000 Old_age Always - 22
195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always - 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
235 Unknown_Attribute 0x0012 099 099 000 Old_age Always - 39
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 272101241210
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 14504 -
5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0
9 Power_On_Hours 0x0032 097 097 000 Old_age Always - 14517
12 Power_Cycle_Count 0x0032 099 099 000 Old_age Always - 87
177 Wear_Leveling_Count 0x0013 053 053 000 Pre-fail Always - 1121
179 Used_Rsvd_Blk_Cnt_Tot 0x0013 100 100 010 Pre-fail Always - 0
181 Program_Fail_Cnt_Total 0x0032 100 100 010 Old_age Always - 0
182 Erase_Fail_Count_Total 0x0032 100 100 010 Old_age Always - 0
183 Runtime_Bad_Block 0x0013 100 100 010 Pre-fail Always - 0
187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0
190 Airflow_Temperature_Cel 0x0032 078 036 000 Old_age Always - 22
195 Hardware_ECC_Recovered 0x001a 200 200 000 Old_age Always - 0
199 UDMA_CRC_Error_Count 0x003e 100 100 000 Old_age Always - 0
235 Unknown_Attribute 0x0012 099 099 000 Old_age Always - 39
241 Total_LBAs_Written 0x0032 099 099 000 Old_age Always - 272101241210
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 14504 -
What I'm looking into now is an error message that shows up right before some zio logs in that wall of text passing by (see attached photos).
blk_update_request I/O error, dev sdb, sector 85928808 op 0x0: (READ) flags phys_seg 1 prio class 0Without knowing to much about these messages my first thought is that it might be a disk error. It just seems a bit unlikely that the disk error would occur at the same time as the BIOS update? Also I had some hopes that mirroring and zfs would help against errors like this, but I'm most likely missing some knowledge in this area.
Any suggestions what to do? I'm not very well familiar with nix command line disk management or ZFS so any recommendations would be appreciated. Let me know if there is any additional information that would help out when solving this.

")