I have a near 2 year old Proxmox install (installed w/latest version at the time and have been keeping it up to date since).
It was built/installed from the beginning with two NVMe SSDs in a ZFS Mirror / RAID1. (With Root on ZFS too). This was all setup right through proxmox and I haven't had any issues.
Nearly a week ago I decided to enable/setup MSISupported (in registry) for a Windows11 VM for an AMD GPU and audio that's been successfully using passthrough since near the beginning. I only gave this new setting a shot because I noticed an occasional audio dropout and the Internet seemed to suggest this would be a fix.
Things seem to be going fine, up until last night however.
I discovered that all my other VMs/CTs were no longer accessible from the internet or network, could no longer hit proxmox web UI.
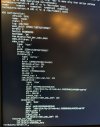
So I check out the local console on the host, and discover a stack trace has been output to the screen and it's hardlocked. Would not respond to keyboard or even a press of the power button, so I held power until it powered off.
Upon booting back up, my zfs pool (named rpool) can no longer be imported by proxmox. It loads the zfs module, runs command: /sbin/zpool import -c /etc/zfs/zpool.cache -N 'rpool' and returns back right away with Cannot Import 'rpool' I/O error , Destroy and re-create the pool from a backup source. Says the same for cachefile too.
GREAT.
At this point I don't know if this is due to the prev/above change, or due to the (random?) lock (which may've been due to AMD GPU reset bug? I was not aware of this or its fix), OR due to the power down after that lock and being brought back up.
I'm dumped off at the initramfs prompt.
zpool list and info (with and without -v) both return 'no pools available'
'zpool import' returns: the name of my pool (rpool), and even says it's ONLINE, it lists the mirror, and both nvme devices (appearing as nvme-eui-....), again, all of them appear ONLINE.
I checked 'ls -l' under /dev/disk/by-id/ and verified that symlinks still exist for all the corresponding entries, everything seems to line up. (Note that in addition to my nvme-eui entries, there's also nvme-Samsung entries, both ones that end and don't end with _1. All of them have corresponding _part1, _part2, _part3 entries too. (three partitions are stock I believe, and the 3rd one being the main/biggest I believe).
Under a separate live CD (using ubuntu server 24.04 LTS and flipping from the install to a new TTY screen), I get all the exact same output for zpool list, status, and import as well. 'lsblk' still returns my nvme devices and their partitions. (though they are not mounted here. and I can't run lsblk from initramfs).
I've run 'smartctl' and verified that all the SMART output there appears fine/correct and it does. I've run 'nvme list' and that seems to return fine/correct stuff. 'nvme smart-log' again, nothing alarming being returned here either for its SMART output too. 'zbd -C -e -p /dev/nvme0n1 rpool' returns a configuration and all that appears to be in order as well (both children/disks listed, paths matching prev output, nothing else alarming etc).
I tried booting into FreeBSD 14.1 earlier but was running into unrelated startup issues (BSD stuff). I can share more but doesn't seem at all related to any of this.
Gparted (live CD) showed both devices just fine too.
I've updated the BIOS on mobo, updated all the settings to match/be correct from prior to update, no change.
I've removed the GPU card entirely and tested all this as well, no change.
I've removed all but one stick of RAM, no change. I've run memtest, no errors being found.
I've been chronicalling all/most of this over here so far / comments / help from other folks, for more pics/output please review these threads.
Initial call for help:
https://furry.engineer/@colinstu/113315894821471446
Next (this) morning after reviewing responses / current status:
https://furry.engineer/@colinstu/113317908970470143
more replies/comments follow in those threads.
I am at a loss at this point. What can I do, is there still any way I can repair or fix my existing zfs pool 'rpool'?
All of my VMs and LXCs are backed up to an 8TB WD SATA drive also present in the machine. My proxmox config/zfs itself however were not backed up.
1) If I can recover w/o reinstalling, this would be the most ideal. What can I try?
2) If I can't recover the pool itself, how can I backup or save all/most of any relevant proxmox config/data that's not included in the guests themselves (host data)? I very much appreciate the steps to do this, or linking to guides/steps elsewhere if they exist.
3) Once #2 is complete above, then I suppose I would feel safe reinstalling Proxmox at that point. Any specific steps on this being different vs a fresh install w/no intent on restorations? Just want to make 100% sure that I don't somehow blow away or mess up my backup drive(s). Eventually I should be able to restore all my VM/LXC backups?
Also is there anything I can check on the old pool to find out what caused this lockup in the first place? Anything I can check that caused this zfs pool issue in the first place?
I appreciate any/all help. Thank you.
It was built/installed from the beginning with two NVMe SSDs in a ZFS Mirror / RAID1. (With Root on ZFS too). This was all setup right through proxmox and I haven't had any issues.
Nearly a week ago I decided to enable/setup MSISupported (in registry) for a Windows11 VM for an AMD GPU and audio that's been successfully using passthrough since near the beginning. I only gave this new setting a shot because I noticed an occasional audio dropout and the Internet seemed to suggest this would be a fix.
Things seem to be going fine, up until last night however.
I discovered that all my other VMs/CTs were no longer accessible from the internet or network, could no longer hit proxmox web UI.
So I check out the local console on the host, and discover a stack trace has been output to the screen and it's hardlocked. Would not respond to keyboard or even a press of the power button, so I held power until it powered off.
Upon booting back up, my zfs pool (named rpool) can no longer be imported by proxmox. It loads the zfs module, runs command: /sbin/zpool import -c /etc/zfs/zpool.cache -N 'rpool' and returns back right away with Cannot Import 'rpool' I/O error , Destroy and re-create the pool from a backup source. Says the same for cachefile too.
GREAT.
At this point I don't know if this is due to the prev/above change, or due to the (random?) lock (which may've been due to AMD GPU reset bug? I was not aware of this or its fix), OR due to the power down after that lock and being brought back up.
I'm dumped off at the initramfs prompt.
zpool list and info (with and without -v) both return 'no pools available'
'zpool import' returns: the name of my pool (rpool), and even says it's ONLINE, it lists the mirror, and both nvme devices (appearing as nvme-eui-....), again, all of them appear ONLINE.
I checked 'ls -l' under /dev/disk/by-id/ and verified that symlinks still exist for all the corresponding entries, everything seems to line up. (Note that in addition to my nvme-eui entries, there's also nvme-Samsung entries, both ones that end and don't end with _1. All of them have corresponding _part1, _part2, _part3 entries too. (three partitions are stock I believe, and the 3rd one being the main/biggest I believe).
Under a separate live CD (using ubuntu server 24.04 LTS and flipping from the install to a new TTY screen), I get all the exact same output for zpool list, status, and import as well. 'lsblk' still returns my nvme devices and their partitions. (though they are not mounted here. and I can't run lsblk from initramfs).
I've run 'smartctl' and verified that all the SMART output there appears fine/correct and it does. I've run 'nvme list' and that seems to return fine/correct stuff. 'nvme smart-log' again, nothing alarming being returned here either for its SMART output too. 'zbd -C -e -p /dev/nvme0n1 rpool' returns a configuration and all that appears to be in order as well (both children/disks listed, paths matching prev output, nothing else alarming etc).
I tried booting into FreeBSD 14.1 earlier but was running into unrelated startup issues (BSD stuff). I can share more but doesn't seem at all related to any of this.
Gparted (live CD) showed both devices just fine too.
I've updated the BIOS on mobo, updated all the settings to match/be correct from prior to update, no change.
I've removed the GPU card entirely and tested all this as well, no change.
I've removed all but one stick of RAM, no change. I've run memtest, no errors being found.
I've been chronicalling all/most of this over here so far / comments / help from other folks, for more pics/output please review these threads.
Initial call for help:
https://furry.engineer/@colinstu/113315894821471446
Next (this) morning after reviewing responses / current status:
https://furry.engineer/@colinstu/113317908970470143
more replies/comments follow in those threads.
I am at a loss at this point. What can I do, is there still any way I can repair or fix my existing zfs pool 'rpool'?
All of my VMs and LXCs are backed up to an 8TB WD SATA drive also present in the machine. My proxmox config/zfs itself however were not backed up.
1) If I can recover w/o reinstalling, this would be the most ideal. What can I try?
2) If I can't recover the pool itself, how can I backup or save all/most of any relevant proxmox config/data that's not included in the guests themselves (host data)? I very much appreciate the steps to do this, or linking to guides/steps elsewhere if they exist.
3) Once #2 is complete above, then I suppose I would feel safe reinstalling Proxmox at that point. Any specific steps on this being different vs a fresh install w/no intent on restorations? Just want to make 100% sure that I don't somehow blow away or mess up my backup drive(s). Eventually I should be able to restore all my VM/LXC backups?
Also is there anything I can check on the old pool to find out what caused this lockup in the first place? Anything I can check that caused this zfs pool issue in the first place?
I appreciate any/all help. Thank you.


")
")