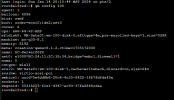
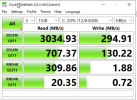
I am doing some testing trying to carve out future deployments for clientele. We are trying to utilize Proxmox and Ceph for an HCI environment that will operate for critical infrastructure systems so HA and live migration for maintenance are very important. The smallest clients we have would have a 3 host system, which I know is not ideal for Ceph, but this is enterprise equipment all with plenty of RAM and 10g+ netwroks so I am hoping to be able to standardize even with the smaller deployements. I have spun up Proxmox on 3 hosts for testing and created a Ceph storage pool running HA and everyhing looked great. I did full network testing and system tuning in an attempt to optmize Ceph, e.g using tuned and setting profile to network-latency but running a windows VM on the Cluster I was suprised by the low perforamance considering the equipment. Per Crysatal Disk Mark I am only getting 187 MB/s sequential write and 107 MB/s sequential read on a test VM running Windows Server 2022. The Ceph pool that is setup is composed of only 3 OSDs that are all NVME drives that were giving about aprox. 3.5 G/s sequential write throuput measured via fio before being added to the Ceph pool. The Ceph Cluster network is 40G w/ jumbo frames that I was getting consistent 34G throughput on measured via Iperf3. I am new to Proxmox and Ceph, almost all of my proffesional experiece is with vmWare but with the Broadcom aquisition we are looking at options. Is there anything I can do to increase my rw speed on windows or is this an issue in regards to windows not playing well with RBD. The test build I had to play with is below.
Node1 AMD Epyc 7764 64 core cpu 256G ram Mellanox Connectx 40g card
Node2 Dual Intel Xenon E52680 28 Core total 128G Ram Mellanox Connactx 40g Card
Node3 Dual Intel Xenon E52680 28 Core total 128G Ram Mellanox Connactx 40g Card
Cisco Nexus Switch QSFP+ 40g
Node1 AMD Epyc 7764 64 core cpu 256G ram Mellanox Connectx 40g card
Node2 Dual Intel Xenon E52680 28 Core total 128G Ram Mellanox Connactx 40g Card
Node3 Dual Intel Xenon E52680 28 Core total 128G Ram Mellanox Connactx 40g Card
Cisco Nexus Switch QSFP+ 40g