Hallo zusammen,
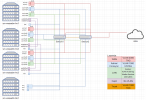
Wir haben ein 3-Node-ProxMox-Cluster mit Ceph und lokalen SSDs im Einsatz. Die SSDs sind per 100Gbit (QSFP-Ports mit DAC-Kabeln) im Mesh-Verbund direkt miteinander verbunden. Unser Cluster lief seit einem Jahr störungsfrei. Bei den Servern handelt es sich um identische Supermicro Dual-Socket Server mit folgender Konfiguration:
Am 28.12.2023 haben wir alle 3 Nodes auf die neue Version 8.1.3 aktualisiert und konnten im Anschluss keine Probleme feststellen. Seit der Nacht auf den 2.1.2024 haben wir nun mit wiederkehrenden Ausfällen eines Nodes zu kämpfen. Es ist immer nur ein Node, aber jedes Mal ein anderer. Der Ausfall äußert sich so: Wir messen den Ping zwischen den Nodes und zu den Mesh-Schnittstellen und können hier keine Auffälligkeiten feststellen (Unter 1ms). Nach einigen Stunden geht der Ping EINES Nodes schlagartig auf 300ms bis mehrere Sekunden hoch, sowohl im Corosync- als auch im Mesh-Netz. Die VMs auf diesem Node verlieren die Verbindung zu Ihren virtuellen Ceph-Festplatten und hängen sich auf. Wir können die VMs von diesem Node nun weder auf einen anderen Node noch von einem anderen Node auf diesen verschieben. Starten wir den Node neu, ist schlagartig wieder alles in Ordnung für ein paar Stunden. Und dann wiederholt sich dasselbe Spiel auf einem anderen Node.
Wir haben ein 3-Node-ProxMox-Cluster mit Ceph und lokalen SSDs im Einsatz. Die SSDs sind per 100Gbit (QSFP-Ports mit DAC-Kabeln) im Mesh-Verbund direkt miteinander verbunden. Unser Cluster lief seit einem Jahr störungsfrei. Bei den Servern handelt es sich um identische Supermicro Dual-Socket Server mit folgender Konfiguration:
- 2x AMD EPYC 7F52 16-Core Processor @ 3.50GHz
- 2 TB RAM
- 2x 500GB SSD (Host, R1), 12x8TB SSD(Ceph)
- 2x Onboard 1Gbit/s NIC (WAN-Netz), 4x 1 Gbit/s NIC via PCIe Karte (2x Corosync/Cluster, 2x LAN Netze), 2x QSFP 100Gbit/s via PCIe Karte (Ceph Netz)
Am 28.12.2023 haben wir alle 3 Nodes auf die neue Version 8.1.3 aktualisiert und konnten im Anschluss keine Probleme feststellen. Seit der Nacht auf den 2.1.2024 haben wir nun mit wiederkehrenden Ausfällen eines Nodes zu kämpfen. Es ist immer nur ein Node, aber jedes Mal ein anderer. Der Ausfall äußert sich so: Wir messen den Ping zwischen den Nodes und zu den Mesh-Schnittstellen und können hier keine Auffälligkeiten feststellen (Unter 1ms). Nach einigen Stunden geht der Ping EINES Nodes schlagartig auf 300ms bis mehrere Sekunden hoch, sowohl im Corosync- als auch im Mesh-Netz. Die VMs auf diesem Node verlieren die Verbindung zu Ihren virtuellen Ceph-Festplatten und hängen sich auf. Wir können die VMs von diesem Node nun weder auf einen anderen Node noch von einem anderen Node auf diesen verschieben. Starten wir den Node neu, ist schlagartig wieder alles in Ordnung für ein paar Stunden. Und dann wiederholt sich dasselbe Spiel auf einem anderen Node.