Hi everyone, I've been encountering severe performance issues recently when backing up a few specific VMs to my PBS.
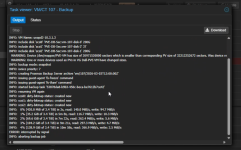
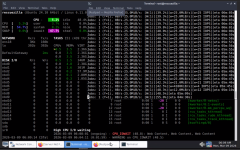
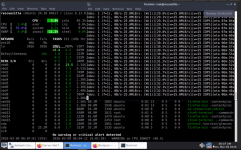
Most of my VMs back up without any issues. However, VMID 107 and two other VMs consistently hang during the process. The progress bar usually gets stuck at a very low percentage. This ultimately causes the guest OS to become completely unresponsive.
Looking at the backup logs, I noticed the message “
Does anyone know why the “
Most of my VMs back up without any issues. However, VMID 107 and two other VMs consistently hang during the process. The progress bar usually gets stuck at a very low percentage. This ultimately causes the guest OS to become completely unresponsive.
Looking at the backup logs, I noticed the message “
dirty-bitmap status: created new”. These VMs are running Informix databases and handle a significant amount of IO load. Even though the QEMU Guest Agent is installed and running correctly, the freeze during the backup makes the systems almost unusable. I've tried manually stopping the task and using “qm unlock 107” to regain control, but I'm worried the same thing will happen during the next backup attempt.Does anyone know why the “
dirty-bitmap status: created new” status appears? Is there a way to prevent the backup process from causing the VM IO to hang? Does this mean my specific VM workload is not suitable for PBS backups?