Hi,
Unfortunately yesterday on a new proxmox VE 7.2.4 with only one VM a new Windows server 2022 same problem ... crash of the VM found turned off for no reason, the server is a new Dell T340 with Perc 330 controller .... now I install the old kernel and I pray it won't happen again as they are servers in production! Why can't this serious problem be solved?
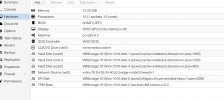
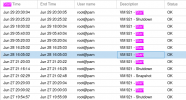
I attach below package versions and part of the syslog, if you need anything else let me know!
... Maybe I repeat myself but this problem is more than a month that we have it from all our customers who have an updated Proxmox VE and who have Windows 2022 servers ... and there are 4 different installations on different servers ... like can we fix it apart from using the old kernel? thank you.
Code:
proxmox-ve: 7.2-1 (running kernel: 5.15.35-2-pve)
pve-manager: 7.2-4 (running version: 7.2-4/ca9d43cc)
pve-kernel-5.15: 7.2-4
pve-kernel-helper: 7.2-4
pve-kernel-5.15.35-2-pve: 5.15.35-5
pve-kernel-5.15.30-2-pve: 5.15.30-3
pve-kernel-5.13.19-6-pve: 5.13.19-15
ceph-fuse: 15.2.16-pve1
corosync: 3.1.5-pve2
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.24-pve1
libproxmox-acme-perl: 1.4.2
libproxmox-backup-qemu0: 1.3.1-1
libpve-access-control: 7.2-2
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.2-2
libpve-guest-common-perl: 4.1-2
libpve-http-server-perl: 4.1-2
libpve-storage-perl: 7.2-4
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 4.0.12-1
lxcfs: 4.0.12-pve1
novnc-pve: 1.3.0-3
proxmox-backup-client: 2.2.3-1
proxmox-backup-file-restore: 2.2.3-1
proxmox-mini-journalreader: 1.3-1
proxmox-widget-toolkit: 3.5.1
pve-cluster: 7.2-1
pve-container: 4.2-1
pve-docs: 7.2-2
pve-edk2-firmware: 3.20210831-2
pve-firewall: 4.2-5
pve-firmware: 3.4-2
pve-ha-manager: 3.3-4
pve-i18n: 2.7-2
pve-qemu-kvm: 6.2.0-10
pve-xtermjs: 4.16.0-1
qemu-server: 7.2-3
smartmontools: 7.2-pve3
spiceterm: 3.2-2
swtpm: 0.7.1~bpo11+1
vncterm: 1.7-1
zfsutils-linux: 2.1.4-pve1
Code:
Jul 01 19:07:26 matrasprox QEMU[79174]: KVM: entry failed, hardware error 0x80000021
Jul 01 19:07:26 matrasprox kernel: set kvm_intel.dump_invalid_vmcs=1 to dump internal KVM state.
Jul 01 19:07:26 matrasprox QEMU[79174]: If you're running a guest on an Intel machine without unrestricted mode
Jul 01 19:07:26 matrasprox QEMU[79174]: support, the failure can be most likely due to the guest entering an invalid
Jul 01 19:07:26 matrasprox QEMU[79174]: state for Intel VT. For example, the guest maybe running in big real mode
Jul 01 19:07:26 matrasprox QEMU[79174]: which is not supported on less recent Intel processors.
Jul 01 19:07:26 matrasprox QEMU[79174]: EAX=000022e2 EBX=63d9e180 ECX=00000001 EDX=00000000
Jul 01 19:07:26 matrasprox QEMU[79174]: ESI=bc81b140 EDI=63daa340 EBP=00000000 ESP=65453d40
Jul 01 19:07:26 matrasprox QEMU[79174]: EIP=00008000 EFL=00000002 [-------] CPL=0 II=0 A20=1 SMM=1 HLT=0
Jul 01 19:07:26 matrasprox QEMU[79174]: ES =0000 00000000 ffffffff 00809300
Jul 01 19:07:26 matrasprox QEMU[79174]: CS =b600 7ffb6000 ffffffff 00809300
Jul 01 19:07:26 matrasprox QEMU[79174]: SS =0000 00000000 ffffffff 00809300
Jul 01 19:07:26 matrasprox QEMU[79174]: DS =0000 00000000 ffffffff 00809300
Jul 01 19:07:26 matrasprox QEMU[79174]: FS =0000 00000000 ffffffff 00809300
Jul 01 19:07:26 matrasprox QEMU[79174]: GS =0000 00000000 ffffffff 00809300
Jul 01 19:07:26 matrasprox QEMU[79174]: LDT=0000 00000000 000fffff 00000000
Jul 01 19:07:26 matrasprox QEMU[79174]: TR =0040 63dad000 00000067 00008b00
Jul 01 19:07:26 matrasprox QEMU[79174]: GDT= 63daefb0 00000057
Jul 01 19:07:26 matrasprox QEMU[79174]: IDT= 00000000 00000000
Jul 01 19:07:26 matrasprox QEMU[79174]: CR0=00050032 CR2=39f33dcc CR3=001ae000 CR4=00000000
Jul 01 19:07:26 matrasprox QEMU[79174]: DR0=0000000000000000 DR1=0000000000000000 DR2=0000000000000000 DR3=0000000000000000
Jul 01 19:07:26 matrasprox QEMU[79174]: DR6=00000000ffff0ff0 DR7=0000000000000400
Jul 01 19:07:26 matrasprox QEMU[79174]: EFER=0000000000000000
Jul 01 19:07:26 matrasprox QEMU[79174]: Code=kvm: ../hw/core/cpu-sysemu.c:77: cpu_asidx_from_attrs: Assertion `ret < cpu->num_ases && ret >= 0' failed.
Jul 01 19:07:26 matrasprox kernel: fwbr1010i0: port 2(tap1010i0) entered disabled state
Jul 01 19:07:26 matrasprox kernel: fwbr1010i0: port 2(tap1010i0) entered disabled state
Jul 01 19:07:26 matrasprox systemd[1]: 1010.scope: Succeeded.
Jul 01 19:07:26 matrasprox systemd[1]: 1010.scope: Consumed 4min 45.838s CPU time.
Jul 01 19:07:26 matrasprox qmeventd[81331]: Starting cleanup for 1010
Jul 01 19:07:26 matrasprox kernel: fwbr1010i0: port 1(fwln1010i0) entered disabled state
Jul 01 19:07:26 matrasprox kernel: vmbr0: port 2(fwpr1010p0) entered disabled state
Jul 01 19:07:26 matrasprox kernel: device fwln1010i0 left promiscuous mode
Jul 01 19:07:26 matrasprox kernel: fwbr1010i0: port 1(fwln1010i0) entered disabled state
Jul 01 19:07:27 matrasprox kernel: device fwpr1010p0 left promiscuous mode
Jul 01 19:07:27 matrasprox kernel: vmbr0: port 2(fwpr1010p0) entered disabled state
Jul 01 19:07:27 matrasprox qmeventd[81331]: Finished cleanup for 1010
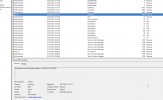
And here attached the conf of VM and the error in Event Viewer on Windows Server 2022 after boot