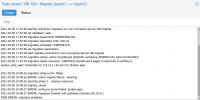
Im testing proxmox and got surprised by the following error:
Running a 3 node hyperconverged cluster with ceph. (pve-manager/6.3-4/0a38c56f (running kernel: 5.4.101-1-pve ; last updated on 04.03.2021 nosub-repo)
I can clone VMs to the other nodes.
I can offline migrate VMs to the other nodes.
But live migration fails.
After 15 minutes it errors out with: broken pipe.
see attached screenshot.
all nodes identical hardware.
Cluster Quorum OK - no apparent error.
Date and Time on all nodes in sync.
firewall off.
All nodes can ping each other on all interfaces.
25gbase direct attached network for ceph
20gbase network (2x 10gbase) for management/migration/backup
1gbase network for corosync
20gbase network (2x 10gbase) for VM traffic but not assigned to VMs at the time of testing
VM Hardware or bios settings make no difference: machine q35 or i440; cpu kvm or epyc ; efi or legacy; no network adapter at time of test assigned;
Windows VM (20H2) with guest agent installed but operating system type makes no difference (tested Linux and Win10)
Any ideas ?
Running a 3 node hyperconverged cluster with ceph. (pve-manager/6.3-4/0a38c56f (running kernel: 5.4.101-1-pve ; last updated on 04.03.2021 nosub-repo)
I can clone VMs to the other nodes.
I can offline migrate VMs to the other nodes.
But live migration fails.
After 15 minutes it errors out with: broken pipe.
see attached screenshot.
all nodes identical hardware.
Cluster Quorum OK - no apparent error.
Date and Time on all nodes in sync.
firewall off.
All nodes can ping each other on all interfaces.
25gbase direct attached network for ceph
20gbase network (2x 10gbase) for management/migration/backup
1gbase network for corosync
20gbase network (2x 10gbase) for VM traffic but not assigned to VMs at the time of testing
VM Hardware or bios settings make no difference: machine q35 or i440; cpu kvm or epyc ; efi or legacy; no network adapter at time of test assigned;
Windows VM (20H2) with guest agent installed but operating system type makes no difference (tested Linux and Win10)
Any ideas ?