Hallo zusammen,
Ich beobachte ein merkwürdiges Verhalten auf 2 Hosts. Wenn ich, zu Testzwecken oder durch real-world load, extreme *schreibende* IO Last erzeuge, kommt es auf dem Host ggfs. zu einer OOM Kondition. Bestenfalls sterben ein paar VMs - schlimmstenfalls stirbt der Host vollständig und muss neugestartet werden.
Meine bisherigen Tests fanden exklusiv auf ZFS statt. Auf einem HDD Array mit striped mirrors (3x 2 disks) und auf einem NVMe Mirror.
Es schaut so aus, als wäre der darunterliegende Storage egal, da das Problem selbst auf NVMe Platten gleichermaßen auftritt.
Auch konnte ich die Problematik scheinbar auf asynchrone Schreibzugriffe festmachen - setze ich das Volume der VM auf sync=always ist das Problem eliminiert, dazu habe ich sogar eine NVMe an meinen HDD Pool geklemmt um das näher zu testen... es lässt sich dort nicht mehr reproduzieren.
Ich habe auch ALLE disk cache modes durchprobiert - überall tritt das gleiche Problem auf, sofern das Volume darunter sync=standard oder sync=disabled gesetzt hat.
Die Problematik passiert NUR, wenn der Load aus der VM kommt - auf dem Host direkt kann ich mit fio Benchmarks drüber laufen lassen wie ich möchte, es kommt nicht zum OOM, der RAM peakt nicht schlagartig, es schaut alles erwartungsgemäß aus.
Ich beobachte das Problem schon einige Tage lang. Durch den ARC sind die Lesewerte exzellent, auch konnte ich keine OOM Kondition erzwingen durch massive Lese Benchmarks.
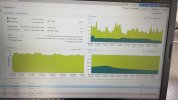
Die Schreibrate ist ebenso extrem (ich rede da von 5-10 GB/s), allerdings stockt dann jegliche I/O Aktivität vollständig und die RAM Nutzung explodiert auf dem Host.
Die Komprimierung könnte die Werte etwas hochtreiben, je nachdem was CrystalDiskMark da produziert an Testdaten, aber der Endeffekt inakzeptabel, egal auf welchem Weg wie viel Last zustande kommt: Der Host frisst sich schlagartig mit RAM voll bis der OOM Killer eingreift.
Wenn ich die Last früh genug wegnehme, stoppt ebenfalls das I/O - allerdings überlebt der Host und knabbert Stück für Stück in ca. 100MB/s Schritten den RAM wieder runter, danach geht das I/O in der VM wie gehabt weiter.
Die Problematik lies sich in Windows 10 VMs auf 2 unterschiedlichen Hosts jeweils reproduzieren - sowohl auf pve-no-subscription als auch pvetest.
In allen Fällen wurden VirtIO Block Disks verwendet, mit discard=on und unter Windows wurden der Qemu Guest Agent sowie die virtio Treiber (stable) installiert.
Ich weiß ehrlich gesagt nicht ganz weiter...
Aus einer Linux VM heraus hab ich das noch nicht probiert, das werde ich noch.
Aktuell schaut es so aus, als gäbe es noch ein weiteres Caching Layer das irgendwie durchdreht - aber wo genau das herkommt kann ich nicht sagen.
Die Hosts sind jeweils mit 64 GB DDR4 RAM ausgestattet, einer mit ECC, einer ohne.
Etwaige Details zur Hardware / Software kann ich gerne alles rausgeben, bitte sagt mir was ihr da brauchen könnt, sonst erstreckt sich das hier bald über 50 Seiten...")
@AST hat das scheinbar gleiche Phänomen, allerdings etwas "milder", bedingt durch Massen an RAM die das Problem kaschieren / abfedern, bevor es kracht.
Eventuell mag er dazu noch nähere Details zu seinem Setup rausgeben.
Positiv anzumerken ist, dass die häufigen Crashes die meine Tests verursacht haben keinerlei Datenverlust produzierten an den VMs, es kam einmalig zu einem Resilver auf dem HDD Array, allerdings sonst keine Vorkommnisse.
ZFS for the win.
Mein aktueller Workaround, um versehentliche VM Crashes zu vermeiden, ist ein NVMe SLOG auf dem HDD Array und sync=always auf dem Pool.
Damit ist das ganze Konstrukt "benchmark proof" bislang.
Aber natürlich ist das keine Problemlösung, drum bitte ich euch um Mithilfe, vielleicht sind wir da einer Sache auf der Spur...
Könnt ihr bei euch im Labor sowas reproduzieren?
TLDR: Windows VM mit VirtIO Disks und virtio-stable Treibern, ZFS als Storage drunter - ein Schreib Benchmark sollte einen massiven RAM Anstieg auslösen und je nach Menge an RAM auch zum OOM führen.
Allerlei sonstige Infos stell ich gerne zur Verfügung, einfach anfragen was ihr braucht.
Erstmal noch frohe Ostern euch allen!
Viele Grüße
Felix
Ich beobachte ein merkwürdiges Verhalten auf 2 Hosts. Wenn ich, zu Testzwecken oder durch real-world load, extreme *schreibende* IO Last erzeuge, kommt es auf dem Host ggfs. zu einer OOM Kondition. Bestenfalls sterben ein paar VMs - schlimmstenfalls stirbt der Host vollständig und muss neugestartet werden.
Meine bisherigen Tests fanden exklusiv auf ZFS statt. Auf einem HDD Array mit striped mirrors (3x 2 disks) und auf einem NVMe Mirror.
Es schaut so aus, als wäre der darunterliegende Storage egal, da das Problem selbst auf NVMe Platten gleichermaßen auftritt.
Auch konnte ich die Problematik scheinbar auf asynchrone Schreibzugriffe festmachen - setze ich das Volume der VM auf sync=always ist das Problem eliminiert, dazu habe ich sogar eine NVMe an meinen HDD Pool geklemmt um das näher zu testen... es lässt sich dort nicht mehr reproduzieren.
Ich habe auch ALLE disk cache modes durchprobiert - überall tritt das gleiche Problem auf, sofern das Volume darunter sync=standard oder sync=disabled gesetzt hat.
Die Problematik passiert NUR, wenn der Load aus der VM kommt - auf dem Host direkt kann ich mit fio Benchmarks drüber laufen lassen wie ich möchte, es kommt nicht zum OOM, der RAM peakt nicht schlagartig, es schaut alles erwartungsgemäß aus.
Ich beobachte das Problem schon einige Tage lang. Durch den ARC sind die Lesewerte exzellent, auch konnte ich keine OOM Kondition erzwingen durch massive Lese Benchmarks.
Die Schreibrate ist ebenso extrem (ich rede da von 5-10 GB/s), allerdings stockt dann jegliche I/O Aktivität vollständig und die RAM Nutzung explodiert auf dem Host.
Die Komprimierung könnte die Werte etwas hochtreiben, je nachdem was CrystalDiskMark da produziert an Testdaten, aber der Endeffekt inakzeptabel, egal auf welchem Weg wie viel Last zustande kommt: Der Host frisst sich schlagartig mit RAM voll bis der OOM Killer eingreift.
Wenn ich die Last früh genug wegnehme, stoppt ebenfalls das I/O - allerdings überlebt der Host und knabbert Stück für Stück in ca. 100MB/s Schritten den RAM wieder runter, danach geht das I/O in der VM wie gehabt weiter.
Die Problematik lies sich in Windows 10 VMs auf 2 unterschiedlichen Hosts jeweils reproduzieren - sowohl auf pve-no-subscription als auch pvetest.
In allen Fällen wurden VirtIO Block Disks verwendet, mit discard=on und unter Windows wurden der Qemu Guest Agent sowie die virtio Treiber (stable) installiert.
Ich weiß ehrlich gesagt nicht ganz weiter...
Aus einer Linux VM heraus hab ich das noch nicht probiert, das werde ich noch.
Aktuell schaut es so aus, als gäbe es noch ein weiteres Caching Layer das irgendwie durchdreht - aber wo genau das herkommt kann ich nicht sagen.
Die Hosts sind jeweils mit 64 GB DDR4 RAM ausgestattet, einer mit ECC, einer ohne.
Etwaige Details zur Hardware / Software kann ich gerne alles rausgeben, bitte sagt mir was ihr da brauchen könnt, sonst erstreckt sich das hier bald über 50 Seiten...
@AST hat das scheinbar gleiche Phänomen, allerdings etwas "milder", bedingt durch Massen an RAM die das Problem kaschieren / abfedern, bevor es kracht.
Eventuell mag er dazu noch nähere Details zu seinem Setup rausgeben.
Positiv anzumerken ist, dass die häufigen Crashes die meine Tests verursacht haben keinerlei Datenverlust produzierten an den VMs, es kam einmalig zu einem Resilver auf dem HDD Array, allerdings sonst keine Vorkommnisse.
ZFS for the win.
Mein aktueller Workaround, um versehentliche VM Crashes zu vermeiden, ist ein NVMe SLOG auf dem HDD Array und sync=always auf dem Pool.
Damit ist das ganze Konstrukt "benchmark proof" bislang.
Aber natürlich ist das keine Problemlösung, drum bitte ich euch um Mithilfe, vielleicht sind wir da einer Sache auf der Spur...
Könnt ihr bei euch im Labor sowas reproduzieren?
TLDR: Windows VM mit VirtIO Disks und virtio-stable Treibern, ZFS als Storage drunter - ein Schreib Benchmark sollte einen massiven RAM Anstieg auslösen und je nach Menge an RAM auch zum OOM führen.
Allerlei sonstige Infos stell ich gerne zur Verfügung, einfach anfragen was ihr braucht.
Erstmal noch frohe Ostern euch allen!
Viele Grüße
Felix
Last edited: