I followed your tip to test only on one but I still have the same problem.
"Jun 24 15:52:07 UBUTESTE kernel: [65400.310058] EXT4-fs warning (device sda2): ext4_trim_all_free:5198: Error -117 loading buddy information for 333
Jun 24 15:52:09 UBUTESTE kernel: [65401.549693] EXT4-fs warning (device sda2): ext4_trim_all_free:5198: Error -117 loading buddy information for 333
Jun 24 15:52:10 UBUTESTE kernel: [65402.565329] EXT4-fs warning (device sda2): ext4_trim_all_free:5198: Error -117 loading buddy information for 333
Jun 24 15:52:12 UBUTESTE kernel: [65404.711834] EXT4-fs warning (device sda2): ext4_trim_all_free:5198: Error -117 loading buddy information for 333
Jun 24 16:00:12 UBUTESTE kernel: [65885.317752] EXT4-fs (sda2): Delayed block allocation failed for inode 9961607 at logical offset 4096 with max blocks 2048 with error 117
Jun 24 16:00:12 UBUTESTE kernel: [65885.320466] EXT4-fs (sda2): This should not happen!! Data will be lost
Jun 24 16:00:12 UBUTESTE kernel: [65885.320466]
Jun 24 16:00:50 UBUTESTE kernel: [65922.911442] EXT4-fs (sda2): Delayed block allocation failed for inode 9961616 at logical offset 61440 with max blocks 2048 with error 117
Jun 24 16:00:50 UBUTESTE kernel: [65922.914905] EXT4-fs (sda2): This should not happen!! Data will be lost
Jun 24 16:00:50 UBUTESTE kernel: [65922.914905]
Jun 24 16:00:58 UBUTESTE kernel: [65930.762299] EXT4-fs (sda2): Delayed block allocation failed for inode 9961617 at logical offset 235520 with max blocks 2048 with error 117
Jun 24 16:00:58 UBUTESTE kernel: [65930.765952] EXT4-fs (sda2): This should not happen!! Data will be lost"
I'm putting more information on the pve settings, if someone can help me I will be very grateful.
lsscsi (each node)
lsblk (each node)
Saida do PVE01
sda 8:0 0 931G 0 disk
├─sda1 8:1 0 1007K 0 part
├─sda2 8:2 0 512M 0 part /boot/efi
└─sda3 8:3 0 930.5G 0 part
├─pve-swap 253:0 0 8G 0 lvm
├─pve-root 253:1 0 96G 0 lvm /
├─pve-data_tmeta 253:2 0 8.1G 0 lvm
│ └─pve-data 253:4 0 794.3G 0 lvm
└─pve-data_tdata 253:3 0 794.3G 0 lvm
└─pve-data 253:4 0 794.3G 0 lvm
sdb 8:16 0 15T 0 disk
└─dell-me-01 253:5 0 15T 0 mpath
├─mpath_dell_vol_proxmox-vm--1001--disk--0 253:6 0 300G 0 lvm
└─mpath_dell_vol_proxmox-vm--10002--disk--0 253:7 0 300G 0 lvm
sdc 8:32 0 15T 0 disk
└─dell-me-01 253:5 0 15T 0 mpath
├─mpath_dell_vol_proxmox-vm--1001--disk--0 253:6 0 300G 0 lvm
└─mpath_dell_vol_proxmox-vm--10002--disk--0 253:7 0 300G 0 lvm
sdd 8:48 0 15T 0 disk
└─dell-me-01 253:5 0 15T 0 mpath
├─mpath_dell_vol_proxmox-vm--1001--disk--0 253:6 0 300G 0 lvm
└─mpath_dell_vol_proxmox-vm--10002--disk--0 253:7 0 300G 0 lvm
sde 8:64 0 15T 0 disk
└─dell-me-01 253:5 0 15T 0 mpath
├─mpath_dell_vol_proxmox-vm--1001--disk--0 253:6 0 300G 0 lvm
└─mpath_dell_vol_proxmox-vm--10002--disk--0 253:7 0 300G 0 lvm
/etc/multipath.conf
defaults {
polling_interval 2
path_selector "round-robin 0"
path_grouping_policy multibus
getuid_callout "/lib/udev/scsi_id -g -u -d /dev/%n"
rr_min_io 100
failback immediate
no_path_retry queue
}
blacklist {
wwid .*
}
blacklist_exceptions {
wwid 3600c0ff00053643c5e2ed26001000000
}
devices {
device {
vendor "DellEMC"
product "ME4084"
path_grouping_policy group_by_prio
prio rdac
#polling_interval 5
path_checker rdac
path_selector "round-robin 0"
hardware_handler "1 rdac"
failback immediate
features "2 pg_init_retries 50"
no_path_retry 30
rr_min_io 100
}
}
multipaths {
multipath {
wwid 3600c0ff00053643c5e2ed26001000000
alias dell-me-01
}
}
Saida do PVE01
mutipath -ll (from each node)
root@pve01:/etc# multipath -ll
dell-me-01 (3600c0ff00053643c5e2ed26001000000) dm-5 DellEMC,ME4
size=15T features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='round-robin 0' prio=30 status=active
|- 15:0:0:0 sdb 8:16 active ready running
|- 17:0:0:0 sdd 8:48 active ready running
|- 16:0:0:0 sdc 8:32 active ready running
`- 18:0:0:0 sde 8:64 active ready running
pvs
root@pve01:/etc# pvs
PV VG Fmt Attr PSize PFree
/dev/mapper/dell-me-01 mpath_dell_vol_proxmox lvm2 a-- <15.00t 14.41t
/dev/sda3 pve lvm2 a-- <930.50g 16.00g
vgs
root@pve01:/etc# vgs
VG #PV #LV #SN Attr VSize VFree
mpath_dell_vol_proxmox 1 2 0 wz--n- <15.00t 14.41t
pve 1 3 0 wz--n- <930.50g 16.00g
lvs
root@pve01:/etc# lvs
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
vm-10002-disk-0 mpath_dell_vol_proxmox -wi-ao---- 300.00g
vm-1001-disk-0 mpath_dell_vol_proxmox -wi-ao---- 300.00g
data pve twi-a-tz-- <794.29g 0.00 0.24
root pve -wi-ao---- 96.00g
swap pve -wi-a----- 8.00g
pvesm status
root@pve01:/etc# pvesm status
Name Type Status Total Used Available %
PATH_ISCSI_LEFT_A0 iscsi active 0 0 0 0.00%
PATH_ISCSI_LEFT_A1 iscsi active 0 0 0 0.00%
PATH_ISCSI_RIGHT_B0 iscsi active 0 0 0 0.00%
PATH_ISCSI_RIGHT_B1 iscsi active 0 0 0 0.00%
local dir active 98559220 80199012 13310660 81.37%
local-lvm lvmthin active 832868352 395112746 437755605 47.44%
mpath_dell_vol_proxmox lvm active 16106123264 1048576000 15057547264 6.51%
pvesm list <storage-name>
root@pve01:/etc# pvesm list mpath_dell_vol_proxmox
Volid Format Type Size VMID
mpath_dell_vol_proxmox:vm-10002-disk-0 raw images 322122547200 10002
mpath_dell_vol_proxmox:vm-1001-disk-0 raw images 322122547200 1001
mpath_dell_vol_proxmox:vm-102-disk-0 raw images 429496729600 102
qm config <vmid>
root@pve01:/etc# qm config 1001
balloon: 0
boot: order=scsi0;net0
cores: 2
memory: 6048
name: UBTESTE
net0: virtio=32:3A:CE:A2:84:B2,bridge=vmbr0,firewall=1
numa: 0
ostype: l26
scsi0: mpath_dell_vol_proxmox:vm-1001-disk-0,discard=on,size=300G
scsihw: virtio-scsi-single
smbios1: uuid=eec333d2-9856-4fbf-bd0c-1c06dcf0140c
sockets: 4
vga: qxl
vmgenid: 76c618ae-d102-41d5-a33e-583100cd04b7
Is there absolutely no errors on the hypervisor side? /var/log/messages? journalctl?
In my log the only error message are these:
Jun 24 10:03:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_00] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 73 to 80
Jun 24 10:03:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_01] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 82 to 83
Jun 24 10:14:00 pve01 rsyslogd: omfwd: TCPSendBuf error -2027, destruct TCP Connection to 10.1.1.16:1514 [v8.1901.0 try
https://www.rsyslog.com/e/2027 ]
Jun 24 12:33:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_00] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 80 to 81
Jun 24 13:03:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_00] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 81 to 84
Jun 24 13:03:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_01] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 83 to 79
Jun 24 14:03:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_00] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 84 to 81
Jun 24 14:03:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_01] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 79 to 84
Jun 24 14:33:56 pve01 smartd[1286]: Device: /dev/bus/0 [megaraid_disk_00] [SAT], SMART Prefailure Attribute: 1 Raw_Read_Error_Rate changed from 81 to 82

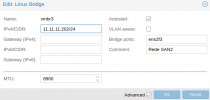
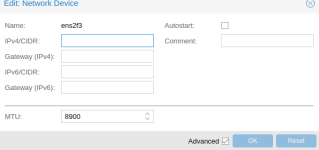
 F:BA,bridge=vmbr0
F:BA,bridge=vmbr0