I know that there are several threads and ressources about not using a raid HBA for PVE with Ceph.
I have some OLD Systems to do some testing and, of course, will not get any money for new hardware for tests.
Those systems have an Areca 1883LP controller. All Disks (Seagate Nytro SSDs 2TB) are in the front enclosure that is directly connected to the Areca controller.
I now have the possibility to create passthrough disks in the controller, in this case no smart data is shown in PVE.
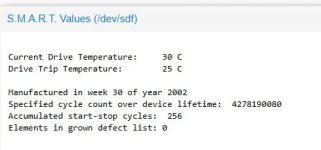
Or i can create a raid-0 with just 1 disk for every hardware disk, then i get smart data shown in PVE, but it is not the real smart data of the disk and does not contain very much information.
What would be the (better) way to get PVE with Ceph running, just for testing. Data loss does not matter in this case, just the basic functionality.
As a workaround: could i install multiple PVE+Ceph as VMs on a PVE server?
I have some OLD Systems to do some testing and, of course, will not get any money for new hardware for tests.
Those systems have an Areca 1883LP controller. All Disks (Seagate Nytro SSDs 2TB) are in the front enclosure that is directly connected to the Areca controller.
I now have the possibility to create passthrough disks in the controller, in this case no smart data is shown in PVE.
Or i can create a raid-0 with just 1 disk for every hardware disk, then i get smart data shown in PVE, but it is not the real smart data of the disk and does not contain very much information.
What would be the (better) way to get PVE with Ceph running, just for testing. Data loss does not matter in this case, just the basic functionality.
As a workaround: could i install multiple PVE+Ceph as VMs on a PVE server?

")
