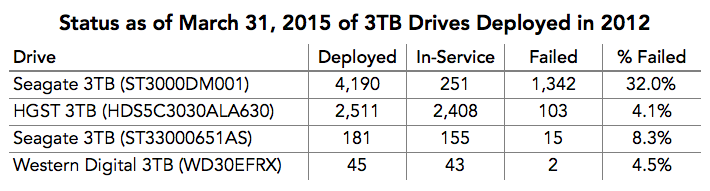
Moin,
Ich habe hier 6 alte HDDs die zwar noch funktionieren aber denen ich keine wichtigen Daten mehr anvertrauen würde. Die habe ich dann in USB3-Gehäuse gesteckt (weil alle meine 10 SATA Ports und 3 PCIe Slots schon belegt sind) um sie in einer VM für unwichtige Daten zu verwenden.
Die HDDs betreiten mir da aber echt Probleme...
Da USB Passthrough für HDDs ja nicht so toll sein soll habe ich die am Host gemounted und dann per "qm set" in die VM "durchgereicht". Sind alles 4K HDDs, laufen über virtio als SCSI mit der Standard 512B Blockgröße von virtio SCSI. Cache mode ist "none", iothreat ist aktiviviert und der Gast ist ein Debian Buster. Partitioniert sind die HDDs alle mit gpt und einer ext4 Partition die auf 1MB ausgerichtet ist. Auf dem Host habe für die HDDs mit hdparm das Spindown deaktiviert (192 war glaube ich der Wert für den Stromsparmodus womit die immer aktiv bleiben sollten). Die drei 3,5" HDD haben ihr eigenes Netzteil und die drei 2,5" HDDs habe ich sowohl direkt am USB2/USB3 Port vom Server wie auch an einem aktiven USB2-Hub getestet.
Zwei von den HDDs (baugleiche 3TB 3,5" HDDs) laufen immer erst einige Stunden und irgendwann bemerke ich, dass da wohl die Verbindung verloren ist. "ls" im Mountpunkt im Gast gibt dann nur noch "I/O error" aus. Wenn ich dann gleichzeitig auf dem Host "lsblk" ansehe, dann fehlen dort auch plotzlich die Laufwerke. Wenn ich die VM stoppe, die beiden USB-Kabel an und wieder abstecke, dann findet "lsblk" die HDDs wieder und ich kann die VM erneut starten. In der Zwischenzeit hat eine der beiden HDDs auch wohl schon ganz den Geist aufgegeben. Die wird jetzt garnicht mehr erkannt und dem Ton nach zu urteilen versucht sie Anzulaufen aber schafft es nicht mehr. Die andere lauft noch, verliert jetzt aber fast sofort immer die Verbindung und SMART spuckt auch täglich neue "uncorrectale sectors" aus.
Dann ist da noch eine andere 4TB 3,5" HDD. Smart-Werte sind bei der OK aber die war leider ein Fehlkauf. Hatte nicht gesehen dass das eine SMR war.
Die Flog aus dem Arbeitsrechner weil Windows immer endlos hing, sobald die mal was schreiben musste. Mittlere Antwortzeit von über 180 Sekunden (ja... nicht Millisekunden) war bei der keine Seltenheit wenn mal eine 50GB ZIP entpackt werden sollte...
Die hat in der VM zwar keine Verbindungsabbrüche, aber sobald ich auf die zugreife wird der Debian Desktop über NoVNC zur Diashow. Die bringt also auch irgendwie Debian total zum stottern. Wenn sie das tut spinnen auch alle Diagramme über das Proxmox WebUI total.
Dann ist da noch eine 1TB 2,5" USB-HDD welche zwar immer verbunden bleibt aber bei jedem lesenden oder schreibenden Zugriff dafür sorgt, dass da die VM Kernel Panics bekommt. Laut dem Syslog hängt dann wohl immer ein CPU thread fest und wird vom Kernel gekillt. Das geht dann so lange so weiter bis der Transfer zu der HDD abgeschlossen ist. Scheint keine Daten zu korrumpieren, aber echt nervig, dass da ganze VM dann immer hängt wenn es alle paar Sekunden zum Kernel Panic kommt.
Auf dem Host im Syslog habe ich dann auch immer Fehler, da die VM dann wohl nicht mehr antwortet und qm in ein Timeout fährt. Ich glaube das stört dann auch die anderen VMs, weil die ganze CPU dann irgendwie hängt...
Und dann sind da noch zwei USB HDDs die meistens funktionieren. Letztens hatten die zwar auch Probleme, aber da waren dann auch plötzich alle USB HDDs vom Host verschwunden. Im syslog des Hosts gab es dann ganz viele USB Kernel Fehler für verschiedenste USB Ports. Da haben dann wohl der PVE Kernel oder USB-Controller vom Mainboard total verrückt gespielt...nach dem Server reboot ging dann wieder alles.
Ich bin da alle möglichen Hardware-Kombinationen durch. Hab USB Ports gewechselt, mit und ohne USB hubs, USB2 und USB3, verschiedenste USB-HDD-Gehäuse und Kabel ausgetestet... ich bekomme es einfach nicht hin dass da etwas mal einen Tag lang nicht verreckt und ich die VM oder gar den ganzen Server neustarten muss.
Komisch fand ich auch noch das Fehlen der Partitionen über "lsblk".
Führe ich "lsblk" auf dem Host aus sehe ich z.B. sdj+sdj1, sdk+sdk1, sdl+sdl1 aber nur sdm, sdn und sdo (also ohne die ext4 Partition).
Mache ich "lsblk" im Gast ist es genau anders herum. Da habe ich dann nur sdj, sdk, sdl aber dafür sdm+sdm1, sdn+sdn1 und sdo+sdo1.
Ist das normal so oder sollten da nicht sowohl im Gast als auch dem Host von lsblk alle Partitionen gefunden werden? Falls das normal so ist... sollten die Partitionen dann im Gast oder auf dem Host zu sehen sein?
3 weitere HDDs habe ich ebenfalls per "qm set" in die selbe VM durchgereicht. Die haben bisher kein einziges Problem gemacht, hängen aber auch per SATA am Mainboard und sind die am wenigsten verschlissenen.
Also irgendwie scheint da USB echt das Problem zu sein.
Hat da vielleicht noch jemand Ideen wie man die Probleme umgehen könnte (außer neue zuverlässige HDDs kaufen") )?
)?
Würde es z.B. etwas bringen können, wenn ich statt einer VM einen privilegierten LXC nehmen würde und den Mountpoint dann per bind-mount in den LXC bringe?
Dann würde ja die zusätzliche Virtualisierung wegfallen. Oder ist dann eventuell der Host mehr gefährdet wenn eine HDD Probleme macht? Wäre natürlich unschön wenn es da auch wieder zu Kernel Fehlern kommt und dann nicht der virtualisierte Kernel Probleme hat sondern der Kernel vom Host, den der LXC ja mitbenutzt.
Ist mir lieber wenn da die VM abstürzt anstatt dem ganzen Host.
Kann ich da vielleicht auch die ganze USB-HDD in den LXC durchreichen anstatt des Bind-mounts vom Mountpoint? Dann könnte ich im LXC ja z. B. ein Script laufen lassen was die HDDs auf Verfügbarkeit abfragt und die ggf bei Problemen unmounted und erneut mounted. Über "qm set" und bind-mounts geht das ja nicht ohne weiteres, da da der Gast nur indirekt Zugriff auf die HDDs hat.
Was mir sonst nur noch einfallen würde wäre einen alten Raspi3 zu nehmen, OMV drauf und dann die HDDs per SMB/NFS in die VM bringen.
Wenn dann was crasht kann es wenigstens nicht den Server stören und ich könnte mir was scripten was die SMB/NFS Shares abfragt und dann zur Not per SSH den Raspi rebooten lässt. Dann könnten Server und VM wenigstens weiterlaufen und müsste nicht ständig neugestartet werden.
War aber eigentlich ganz froh inzwischen meine letzten Raspis ausgemustert und alles auf den Proxmox-Server verlagert zu haben...
Ich habe hier 6 alte HDDs die zwar noch funktionieren aber denen ich keine wichtigen Daten mehr anvertrauen würde. Die habe ich dann in USB3-Gehäuse gesteckt (weil alle meine 10 SATA Ports und 3 PCIe Slots schon belegt sind) um sie in einer VM für unwichtige Daten zu verwenden.
Die HDDs betreiten mir da aber echt Probleme...
Da USB Passthrough für HDDs ja nicht so toll sein soll habe ich die am Host gemounted und dann per "qm set" in die VM "durchgereicht". Sind alles 4K HDDs, laufen über virtio als SCSI mit der Standard 512B Blockgröße von virtio SCSI. Cache mode ist "none", iothreat ist aktiviviert und der Gast ist ein Debian Buster. Partitioniert sind die HDDs alle mit gpt und einer ext4 Partition die auf 1MB ausgerichtet ist. Auf dem Host habe für die HDDs mit hdparm das Spindown deaktiviert (192 war glaube ich der Wert für den Stromsparmodus womit die immer aktiv bleiben sollten). Die drei 3,5" HDD haben ihr eigenes Netzteil und die drei 2,5" HDDs habe ich sowohl direkt am USB2/USB3 Port vom Server wie auch an einem aktiven USB2-Hub getestet.
Zwei von den HDDs (baugleiche 3TB 3,5" HDDs) laufen immer erst einige Stunden und irgendwann bemerke ich, dass da wohl die Verbindung verloren ist. "ls" im Mountpunkt im Gast gibt dann nur noch "I/O error" aus. Wenn ich dann gleichzeitig auf dem Host "lsblk" ansehe, dann fehlen dort auch plotzlich die Laufwerke. Wenn ich die VM stoppe, die beiden USB-Kabel an und wieder abstecke, dann findet "lsblk" die HDDs wieder und ich kann die VM erneut starten. In der Zwischenzeit hat eine der beiden HDDs auch wohl schon ganz den Geist aufgegeben. Die wird jetzt garnicht mehr erkannt und dem Ton nach zu urteilen versucht sie Anzulaufen aber schafft es nicht mehr. Die andere lauft noch, verliert jetzt aber fast sofort immer die Verbindung und SMART spuckt auch täglich neue "uncorrectale sectors" aus.
Dann ist da noch eine andere 4TB 3,5" HDD. Smart-Werte sind bei der OK aber die war leider ein Fehlkauf. Hatte nicht gesehen dass das eine SMR war.
Die Flog aus dem Arbeitsrechner weil Windows immer endlos hing, sobald die mal was schreiben musste. Mittlere Antwortzeit von über 180 Sekunden (ja... nicht Millisekunden) war bei der keine Seltenheit wenn mal eine 50GB ZIP entpackt werden sollte...
Die hat in der VM zwar keine Verbindungsabbrüche, aber sobald ich auf die zugreife wird der Debian Desktop über NoVNC zur Diashow. Die bringt also auch irgendwie Debian total zum stottern. Wenn sie das tut spinnen auch alle Diagramme über das Proxmox WebUI total.
Dann ist da noch eine 1TB 2,5" USB-HDD welche zwar immer verbunden bleibt aber bei jedem lesenden oder schreibenden Zugriff dafür sorgt, dass da die VM Kernel Panics bekommt. Laut dem Syslog hängt dann wohl immer ein CPU thread fest und wird vom Kernel gekillt. Das geht dann so lange so weiter bis der Transfer zu der HDD abgeschlossen ist. Scheint keine Daten zu korrumpieren, aber echt nervig, dass da ganze VM dann immer hängt wenn es alle paar Sekunden zum Kernel Panic kommt.
Auf dem Host im Syslog habe ich dann auch immer Fehler, da die VM dann wohl nicht mehr antwortet und qm in ein Timeout fährt. Ich glaube das stört dann auch die anderen VMs, weil die ganze CPU dann irgendwie hängt...
Und dann sind da noch zwei USB HDDs die meistens funktionieren. Letztens hatten die zwar auch Probleme, aber da waren dann auch plötzich alle USB HDDs vom Host verschwunden. Im syslog des Hosts gab es dann ganz viele USB Kernel Fehler für verschiedenste USB Ports. Da haben dann wohl der PVE Kernel oder USB-Controller vom Mainboard total verrückt gespielt...nach dem Server reboot ging dann wieder alles.
Ich bin da alle möglichen Hardware-Kombinationen durch. Hab USB Ports gewechselt, mit und ohne USB hubs, USB2 und USB3, verschiedenste USB-HDD-Gehäuse und Kabel ausgetestet... ich bekomme es einfach nicht hin dass da etwas mal einen Tag lang nicht verreckt und ich die VM oder gar den ganzen Server neustarten muss.
Komisch fand ich auch noch das Fehlen der Partitionen über "lsblk".
Führe ich "lsblk" auf dem Host aus sehe ich z.B. sdj+sdj1, sdk+sdk1, sdl+sdl1 aber nur sdm, sdn und sdo (also ohne die ext4 Partition).
Mache ich "lsblk" im Gast ist es genau anders herum. Da habe ich dann nur sdj, sdk, sdl aber dafür sdm+sdm1, sdn+sdn1 und sdo+sdo1.
Ist das normal so oder sollten da nicht sowohl im Gast als auch dem Host von lsblk alle Partitionen gefunden werden? Falls das normal so ist... sollten die Partitionen dann im Gast oder auf dem Host zu sehen sein?
3 weitere HDDs habe ich ebenfalls per "qm set" in die selbe VM durchgereicht. Die haben bisher kein einziges Problem gemacht, hängen aber auch per SATA am Mainboard und sind die am wenigsten verschlissenen.
Also irgendwie scheint da USB echt das Problem zu sein.
Hat da vielleicht noch jemand Ideen wie man die Probleme umgehen könnte (außer neue zuverlässige HDDs kaufen
)?Würde es z.B. etwas bringen können, wenn ich statt einer VM einen privilegierten LXC nehmen würde und den Mountpoint dann per bind-mount in den LXC bringe?
Dann würde ja die zusätzliche Virtualisierung wegfallen. Oder ist dann eventuell der Host mehr gefährdet wenn eine HDD Probleme macht? Wäre natürlich unschön wenn es da auch wieder zu Kernel Fehlern kommt und dann nicht der virtualisierte Kernel Probleme hat sondern der Kernel vom Host, den der LXC ja mitbenutzt.
Ist mir lieber wenn da die VM abstürzt anstatt dem ganzen Host.
Kann ich da vielleicht auch die ganze USB-HDD in den LXC durchreichen anstatt des Bind-mounts vom Mountpoint? Dann könnte ich im LXC ja z. B. ein Script laufen lassen was die HDDs auf Verfügbarkeit abfragt und die ggf bei Problemen unmounted und erneut mounted. Über "qm set" und bind-mounts geht das ja nicht ohne weiteres, da da der Gast nur indirekt Zugriff auf die HDDs hat.
Was mir sonst nur noch einfallen würde wäre einen alten Raspi3 zu nehmen, OMV drauf und dann die HDDs per SMB/NFS in die VM bringen.
Wenn dann was crasht kann es wenigstens nicht den Server stören und ich könnte mir was scripten was die SMB/NFS Shares abfragt und dann zur Not per SSH den Raspi rebooten lässt. Dann könnten Server und VM wenigstens weiterlaufen und müsste nicht ständig neugestartet werden.
War aber eigentlich ganz froh inzwischen meine letzten Raspis ausgemustert und alles auf den Proxmox-Server verlagert zu haben...
Last edited: