i want to upgrade from pve7 to pve8,so i upgrade ceph first. I follow the help doc:https://pve.proxmox.com/wiki/Ceph_Pacific_to_Quincy
upgrade process looks like ok,but when i restarted osds,most of osds were in but down.

no more helpful log but this:
it seams cluster limit osd release,when osd upgraded to quincy,it broken.
when i run this script:
it's my mon dump:

it's my osd dump,i omit some pool infos.

some other log about osd release:
anyone can help me? will i lose my data?
thanks a lot.
my pve version
ceph version
why my osds version are not quincy?
upgrade process looks like ok,but when i restarted osds,most of osds were in but down.
no more helpful log but this:
2023-12-16T04:16:40.237470+0800 mon.pve (mon.2) 12703 : cluster [INF] disallowing boot of quincy+ OSD osd.0 v2:192.168.3.5:6808/720073 because require_osd_release < octopus
it seams cluster limit osd release,when osd upgraded to quincy,it broken.
when i run this script:
it stucked and all mon will be deadceph osd require-osd-release quincy
it's my mon dump:
it's my osd dump,i omit some pool infos.
some other log about osd release:
2023-12-16T04:59:59.999+0800 7f83cf1dd700 0 log_channel(cluster) log [WRN] : [WRN] OSD_UPGRADE_FINISHED: all OSDs are running pacific or later but require_osd_release < pacific
2023-12-16T04:59:59.999+0800 7f83cf1dd700 0 log_channel(cluster) log [WRN] : all OSDs are running pacific or later but require_osd_release < pacific
3-12-16T05:57:55.469+0800 7f262efbf3c0 0 osd.3 2065970 crush map has features 288514119978713088, adjusting msgr requires for clients
2023-12-16T05:57:55.469+0800 7f262efbf3c0 0 osd.3 2065970 crush map has features 288514119978713088 was 8705, adjusting msgr requires for mons
2023-12-16T05:57:55.469+0800 7f262efbf3c0 0 osd.3 2065970 crush map has features 3314933069571702784, adjusting msgr requires for osds
2023-12-16T05:57:55.469+0800 7f262efbf3c0 1 osd.3 2065970 check_osdmap_features require_osd_release unknown -> nautilus
anyone can help me? will i lose my data?
thanks a lot.
my pve version
pve-manager/7.4-17/513c62be (running kernel: 5.15.131-2-pve)
root@pve6:~# pveversions
-bash: pveversions: command not found
root@pve6:~# pveversion -v
proxmox-ve: 7.4-1 (running kernel: 5.15.131-2-pve)
pve-manager: 7.4-17 (running version: 7.4-17/513c62be)
pve-kernel-5.15: 7.4-9
pve-kernel-5.13: 7.1-9
pve-kernel-5.4: 6.4-6
pve-kernel-5.15.131-2-pve: 5.15.131-3
pve-kernel-5.15.126-1-pve: 5.15.126-1
pve-kernel-5.15.116-1-pve: 5.15.116-1
pve-kernel-5.15.108-1-pve: 5.15.108-2
pve-kernel-5.13.19-6-pve: 5.13.19-15
pve-kernel-5.13.19-2-pve: 5.13.19-4
pve-kernel-5.4.140-1-pve: 5.4.140-1
pve-kernel-5.4.34-1-pve: 5.4.34-2
ceph: 17.2.6-pve1
ceph-fuse: 17.2.6-pve1
corosync: 3.1.7-pve1
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown: residual config
ifupdown2: 3.1.0-1+pmx4
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.24-pve2
libproxmox-acme-perl: 1.4.4
libproxmox-backup-qemu0: 1.3.1-1
libproxmox-rs-perl: 0.2.1
libpve-access-control: 7.4.1
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.4-2
libpve-guest-common-perl: 4.2-4
libpve-http-server-perl: 4.2-3
libpve-rs-perl: 0.7.7
libpve-storage-perl: 7.4-3
libqb0: 1.0.5-1
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 5.0.2-2
lxcfs: 5.0.3-pve1
novnc-pve: 1.4.0-1
proxmox-backup-client: 2.4.4-1
proxmox-backup-file-restore: 2.4.4-1
proxmox-kernel-helper: 7.4-1
proxmox-mail-forward: 0.1.1-1
proxmox-mini-journalreader: 1.3-1
proxmox-offline-mirror-helper: 0.5.2
proxmox-widget-toolkit: 3.7.3
pve-cluster: 7.3-3
pve-container: 4.4-6
pve-docs: 7.4-2
pve-edk2-firmware: 3.20230228-4~bpo11+1
pve-firewall: 4.3-5
pve-firmware: 3.6-6
pve-ha-manager: 3.6.1
pve-i18n: 2.12-1
pve-qemu-kvm: 7.2.0-8
pve-xtermjs: 4.16.0-2
qemu-server: 7.4-4
smartmontools: 7.2-pve3
spiceterm: 3.2-2
swtpm: 0.8.0~bpo11+3
vncterm: 1.7-1
zfsutils-linux: 2.1.14-pve1
ceph version
root@pve6:~# ceph versions
{
"mon": {
"ceph version 17.2.6 (995dec2cdae920da21db2d455e55efbc339bde24) quincy (stable)": 3
},
"mgr": {
"ceph version 17.2.6 (995dec2cdae920da21db2d455e55efbc339bde24) quincy (stable)": 3
},
"osd": {
"ceph version 16.2.13 (b81a1d7f978c8d41cf452da7af14e190542d2ee2) pacific (stable)": 2
},
"mds": {},
"overall": {
"ceph version 16.2.13 (b81a1d7f978c8d41cf452da7af14e190542d2ee2) pacific (stable)": 2,
"ceph version 17.2.6 (995dec2cdae920da21db2d455e55efbc339bde24) quincy (stable)": 6
}
}
why my osds version are not quincy?
Attachments

Last edited:



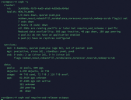

 ctopus)
ctopus)
 repare_command_impl(boost::intrusive_ptr<MonOpRequest>, std::map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, boost::variant<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, long, double, std::vector<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::allocator<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::vector<long, std::allocator<long> >, std::vector<double, std::allocator<double> > >, std::less<void>, std::allocator<std:
repare_command_impl(boost::intrusive_ptr<MonOpRequest>, std::map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, boost::variant<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool, long, double, std::vector<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::allocator<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >, std::vector<long, std::allocator<long> >, std::vector<double, std::allocator<double> > >, std::less<void>, std::allocator<std: ispatchThread::entry()+0xd) [0x7f66ae00e1cd]
ispatchThread::entry()+0xd) [0x7f66ae00e1cd]


