Hi,
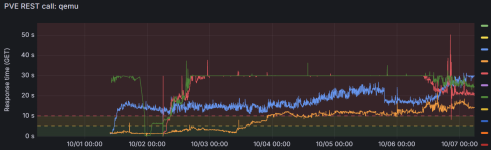
after upgrading to PVE 9 we realised that for some cluster nodes our calls to a node's qemu endpoint (api2/json/nodes/<node>/qemu) started to fail (HTTP 592/593). It looks like a timeout as it's consistent. They terminate after roughly 30s. Some work but need >> 10s to complete.
We added some monitoring and saw some interesting figures: after a reboot it typically is quite ok (way below 10s). When starting up all VMs (about 30-50) it still was ok... after some time it grew worse. We overcommit intentionally but keep the load as well as CPU and memory usage in a viable range. Most nodes do have a swap partition on an Optane disk (~700 GB), some use a dedicated NVMe disk. KSM is max 50 GB, typically much lower.
There was no issue with PVE 8.
Our rough node cluster specs are:
* 13 Nodes
* 64 physical cores on each node (2x EPYC 7502 or EPYC 7H12 or EPYC 9354)
* 1TB RAM each
* All-NVMe
* Ceph + small local ZFS pool
* Frontend 10 GbE
* Ceph 100 GbE
With no change to the spec it got worse just after upgrading to PVE 9. Any idea what to look for or check?
Thanks
phb
after upgrading to PVE 9 we realised that for some cluster nodes our calls to a node's qemu endpoint (api2/json/nodes/<node>/qemu) started to fail (HTTP 592/593). It looks like a timeout as it's consistent. They terminate after roughly 30s. Some work but need >> 10s to complete.
We added some monitoring and saw some interesting figures: after a reboot it typically is quite ok (way below 10s). When starting up all VMs (about 30-50) it still was ok... after some time it grew worse. We overcommit intentionally but keep the load as well as CPU and memory usage in a viable range. Most nodes do have a swap partition on an Optane disk (~700 GB), some use a dedicated NVMe disk. KSM is max 50 GB, typically much lower.
There was no issue with PVE 8.
Our rough node cluster specs are:
* 13 Nodes
* 64 physical cores on each node (2x EPYC 7502 or EPYC 7H12 or EPYC 9354)
* 1TB RAM each
* All-NVMe
* Ceph + small local ZFS pool
* Frontend 10 GbE
* Ceph 100 GbE
With no change to the spec it got worse just after upgrading to PVE 9. Any idea what to look for or check?
Thanks
phb
Attachments
Last edited:
")
