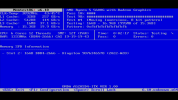
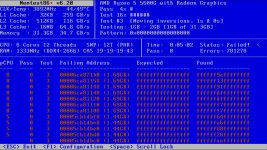
我的服务器都尝试过安装6.X、7.X、8.X所有的版本,
I have tried installing all versions, including 6.X, 7.X, and 8.X, on my server.
使用一段时间后(比如在安装虚拟机过程中,切换到浏览器别的页面再切换回来)就都会出现页面unknown的情况,
After using it for a while (such as during the virtual machine installation process, switching to other pages in the browser, and then switching back), the page status will become 'unknown.'
每当出现unknown的状态,使用命令“systemctl status pvestatd”就能恢复,
Whenever the 'unknown' status occurs, using the command "systemctl status pvestatd" can restore it.
但过一会又有问题,这种时候就只能拔掉服务器电源重启服务器。
However, after a while, the issue reoccurs, and in such cases, I have to unplug the server's power to restart it.
难道是我的服务器硬件有问题吗?
Could it be an issue with my server's hardware?
我的主板是A520SD4-ITX 搭配AMD5600G的CPU,
My motherboard is A520SD4-ITX paired with an AMD5600G CPU.
主板的BIOS已经把虚拟化开起来了,还有别的地方要设置?
The motherboard's BIOS has already enabled virtualization. Are there any other settings that need to be configured?
我还需要提供什么信息
What other information do I need to provide?




I have tried installing all versions, including 6.X, 7.X, and 8.X, on my server.
使用一段时间后(比如在安装虚拟机过程中,切换到浏览器别的页面再切换回来)就都会出现页面unknown的情况,
After using it for a while (such as during the virtual machine installation process, switching to other pages in the browser, and then switching back), the page status will become 'unknown.'
每当出现unknown的状态,使用命令“systemctl status pvestatd”就能恢复,
Whenever the 'unknown' status occurs, using the command "systemctl status pvestatd" can restore it.
但过一会又有问题,这种时候就只能拔掉服务器电源重启服务器。
However, after a while, the issue reoccurs, and in such cases, I have to unplug the server's power to restart it.
难道是我的服务器硬件有问题吗?
Could it be an issue with my server's hardware?
我的主板是A520SD4-ITX 搭配AMD5600G的CPU,
My motherboard is A520SD4-ITX paired with an AMD5600G CPU.
主板的BIOS已经把虚拟化开起来了,还有别的地方要设置?
The motherboard's BIOS has already enabled virtualization. Are there any other settings that need to be configured?
我还需要提供什么信息
What other information do I need to provide?