Hi, thanks for your assistance, i attach the required info:
currently this is a test environment
pveversion:
proxmox-ve: 8.1.0 (running kernel: 6.5.11-7-pve)
pve-manager: 8.1.3 (running version: 8.1.3/b46aac3b42da5d15)
proxmox-kernel-helper: 8.1.0
pve-kernel-5.15: 7.4-8
proxmox-kernel-6.5: 6.5.11-7
proxmox-kernel-6.5.11-7-pve-signed: 6.5.11-7
proxmox-kernel-6.5.11-6-pve-signed: 6.5.11-6
pve-kernel-5.15.131-1-pve: 5.15.131-2
pve-kernel-5.15.30-2-pve: 5.15.30-3
ceph-fuse: 16.2.11+ds-2
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx8
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-4
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.0
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.3
libpve-access-control: 8.0.7
libpve-apiclient-perl: 3.3.1
libpve-common-perl: 8.1.0
libpve-guest-common-perl: 5.0.6
libpve-http-server-perl: 5.0.5
libpve-network-perl: 0.9.5
libpve-rs-perl: 0.8.7
libpve-storage-perl: 8.0.5
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 5.0.2-4
lxcfs: 5.0.3-pve4
novnc-pve: 1.4.0-3
proxmox-backup-client: 3.1.2-1
proxmox-backup-file-restore: 3.1.2-1
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.2.2
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.3
proxmox-widget-toolkit: 4.1.3
pve-cluster: 8.0.5
pve-container: 5.0.8
pve-docs: 8.1.3
pve-edk2-firmware: 4.2023.08-2
pve-firewall: 5.0.3
pve-firmware: 3.9-1
pve-ha-manager: 4.0.3
pve-i18n: 3.1.5
pve-qemu-kvm: 8.1.2-6
pve-xtermjs: 5.3.0-3
qemu-server: 8.0.10
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.2-pve1
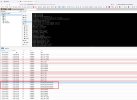
qm config 100:
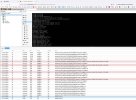
 qm config 103
qm config 103

the rest of the VM's have similar configuration and not setting Start at boot:
the journal is the attached file.
the physical cpu:
Intel(R) Core(TM) i3-8100T CPU @ 3.10GHz 4 CORES
rest of config of the "server"
RAM 12GB
SSD 512GB.
I tried to start 2 virtual machines, and then a boot loop started, I was able to stop it by stopping the pvescheduler.service service.
thanks in advance for your assistance.