Today, for the second time, I had this problem.
Suddenly some virtual machines start to become unreachable.
Gradually all the machines begin to have problems.
Full RAM usage is reported first, and shortly thereafter, they become unreachable.
The only way to fix is to stop many VMs and restart them a few at a time.
Even after a restart of proxmox the problem arises.
Unfortunately no other details on the problem.
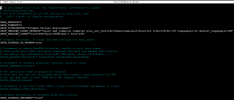
I attach the syslog and the grub file.
From there you can see that the problem started at 16:41:48 (row 964) and then no longer showed up after the 17:09:19 (row 2092).
Tell me what other information you may need.
Suddenly some virtual machines start to become unreachable.
Gradually all the machines begin to have problems.
Full RAM usage is reported first, and shortly thereafter, they become unreachable.
The only way to fix is to stop many VMs and restart them a few at a time.
Even after a restart of proxmox the problem arises.
Unfortunately no other details on the problem.
I attach the syslog and the grub file.
From there you can see that the problem started at 16:41:48 (row 964) and then no longer showed up after the 17:09:19 (row 2092).
Tell me what other information you may need.