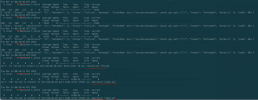
I have a very strange problem on my local network and my PVE.
Brand new server, 10Gb ixgbe network card connected via SFP+ to a 10Gb switch. A couple of VMs and some other computers on my local network. The new server is replacing an older machine, the VMs were copied to the new server. The setup is a replica of what I had before. Very simple setup, fixed IP and 1 vmbr shared by all the VMs.
So, working as expected and used to work before :
- network between laptop and host
- network between laptop and VMs
- network between host and VMs
- internet access (everyone)
Not working (and used to work with almost identical setup) :
- network between VMs
The firewall is disabled on VMs, enabled on host (the host is accessible via internet, the VMs are accessible via a reverse proxy on my firewall - OPNsense on a separate machine).
The behavior is very strange, it's not that I have no network at all between the VMs. They can ping each other, I can ssh from one to another, but as soon as there is files involved, the network link falls apart. For example, I start a web ui, I am getting a timeout error. I start scp, it starts but gets stalled. I can mount a SMB or NFS share, no errors, but as soon as I list a directory with files in it, same thing... stalled... timeout.
It took me a while to understand what's working and what's not. I have not really a clue where to begin to search...
Any help ?
Brand new server, 10Gb ixgbe network card connected via SFP+ to a 10Gb switch. A couple of VMs and some other computers on my local network. The new server is replacing an older machine, the VMs were copied to the new server. The setup is a replica of what I had before. Very simple setup, fixed IP and 1 vmbr shared by all the VMs.
So, working as expected and used to work before :
- network between laptop and host
- network between laptop and VMs
- network between host and VMs
- internet access (everyone)
Not working (and used to work with almost identical setup) :
- network between VMs
The firewall is disabled on VMs, enabled on host (the host is accessible via internet, the VMs are accessible via a reverse proxy on my firewall - OPNsense on a separate machine).
The behavior is very strange, it's not that I have no network at all between the VMs. They can ping each other, I can ssh from one to another, but as soon as there is files involved, the network link falls apart. For example, I start a web ui, I am getting a timeout error. I start scp, it starts but gets stalled. I can mount a SMB or NFS share, no errors, but as soon as I list a directory with files in it, same thing... stalled... timeout.
It took me a while to understand what's working and what's not. I have not really a clue where to begin to search...
Any help ?