hallo zusammen,
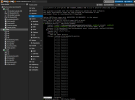
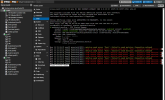
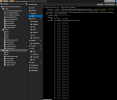
in meiner kleinen Testumgebung bestehend aus einem Cluster mit 3 Nodes beobachte ich hin und wieder das Elemente/Objekte wie z.b. VMs oder Speicher mit einem grauen Fragezeichen (Status: unknown) gekennzeichnet werden.
Nach einem Neustart ist erstmal wieder alles gut. Tritt aber hin und wieder auch nach langer Wartezeit wieder auf. Sieht erstmal nach Anzeigefehler aus, da der Status z.b. von Speicher abrufbar ist oder laufende VMs in der Konsole angezeigt werden.
Was passiert da und wie kann ich das Problem lösen, ohne den betroffen Node neu zu starten?

in meiner kleinen Testumgebung bestehend aus einem Cluster mit 3 Nodes beobachte ich hin und wieder das Elemente/Objekte wie z.b. VMs oder Speicher mit einem grauen Fragezeichen (Status: unknown) gekennzeichnet werden.
Nach einem Neustart ist erstmal wieder alles gut. Tritt aber hin und wieder auch nach langer Wartezeit wieder auf. Sieht erstmal nach Anzeigefehler aus, da der Status z.b. von Speicher abrufbar ist oder laufende VMs in der Konsole angezeigt werden.
Was passiert da und wie kann ich das Problem lösen, ohne den betroffen Node neu zu starten?
Last edited: