Hi ich setze Proxmox jetzt seit 3 Monaten bei einem Kunden ein. In dieser Zeit hatte ich 7 Vorfälle, in denen VMs einfach so zerstört wurden und aus Backups wiederhergestellt werden mussten.
Der Kunde hat 5 Windows-Server VMs auf einem physischen Server, der mit Proxmox virtualisiert ist. Insgesamt 6 Festplatten, 2 SSD, 4 HDD, die HDDs sind per ZFS "Raid" kombiniert und die 2 SSDs als Write-Cache ebenfalls ausfallsicher eingebunden. Der server hat keinen SWAP aber 128 GB Ram. Die VMs belegen etwa 64 GB Ram, für ZFS ist also genug übrig.
Nachts läuft ein Backup über alle VMs mit ZSTD Compression. Morgens sind dann einige VMs frozen, oder kaputt.
Die Systeme sind wie folgt eingestellt:
- BIOS OVMF (UEFI)
- Machine pc-i440fx-6.1 oder pc-q35-5.1
- SCSCI Controller VirtIO SCSI
- DVD/Rom (leer)
- Hard Disks (SCSI): aio=threads,cache=writethrough,iothread=1
ich hab auch schon io_uring probiert. Führt auch zu Fehlern.
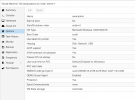
Hier ein Beispiel:


Wie kann es sein, dass ich ständig Daten verliere? Was mache ich falsch?
Der Kunde hat 5 Windows-Server VMs auf einem physischen Server, der mit Proxmox virtualisiert ist. Insgesamt 6 Festplatten, 2 SSD, 4 HDD, die HDDs sind per ZFS "Raid" kombiniert und die 2 SSDs als Write-Cache ebenfalls ausfallsicher eingebunden. Der server hat keinen SWAP aber 128 GB Ram. Die VMs belegen etwa 64 GB Ram, für ZFS ist also genug übrig.
Nachts läuft ein Backup über alle VMs mit ZSTD Compression. Morgens sind dann einige VMs frozen, oder kaputt.
Die Systeme sind wie folgt eingestellt:
- BIOS OVMF (UEFI)
- Machine pc-i440fx-6.1 oder pc-q35-5.1
- SCSCI Controller VirtIO SCSI
- DVD/Rom (leer)
- Hard Disks (SCSI): aio=threads,cache=writethrough,iothread=1
ich hab auch schon io_uring probiert. Führt auch zu Fehlern.
Hier ein Beispiel:
Wie kann es sein, dass ich ständig Daten verliere? Was mache ich falsch?
Last edited:
")
")
