Hey everyone,
I recently upgraded the HBA in a Dell R720 with one that supports IT mode. This host was in a 3-node cluster with Ceph. When I booted after the HBA replacement, the rpool could not be imported, and I was taken to the initramfs prompt. Instead of just importing the rpool and then following this thread https://www.reddit.com/r/Proxmox/comments/fbdgos/cannot_import_rpool_automatically/ to just change the sleep values for ZFS_INITRD_PRE_MOUNTROOT_SLEEP and ZFS_INITRD_POST_MODPROBE_SLEEP in /etc/default/zfs, I decided to just reinstall Proxmox on the host. After reinstalling Proxmox on the host, I ran into the same issue at boot but was able to fix the issue by changing those sleep values. After configuring network settings and rejoining the cluster and following the instructions from this thread https://forum.proxmox.com/threads/reinstall-pve-node-with-ceph.59665/, I was able to get everything back up. Here is what I did:
1. Install Proxmox again
2. Recover networking settings (can be retrieved from another working node).
3. Make sure /etc/resolv.conf /etc/apt/sources /etc/hosts are all correct.
4. Join node to cluster (sometimes you will have to remove the failed node first. ie: pvecm rm nodename)
5. Install Ceph on the new node
6. Remove old failed node monitor.
- ceph mon rm nodename
- remove IP from mon_host in /etc/ceph/ceph.conf
7. Create monitor for new node - resource: https://docs.ceph.com/en/nautilus/rados/operations/add-or-rm-mons/
- follow steps for adding a monitor manually
- make sure that the /var/lib/ceph/mon/nodename directory is owned by the user ceph (because that is the user that the ceph monitor service runs as)
- monitor keyring can be retrieved from another working host at /etc/pve/priv/ceph.mon.keyring
- monitor map is retrieved by running: ceph mon getmap > monmap.file on a working host in the cluster.
- port number is not necessary on the last step: ceph-mon -i nodename --public-addr 172.16.1.xx
8. Run: ceph-volume lvm activate --all
9. In the Gui, go to the node->Ceph->OSD and click the OSD for the new node and then click the start button.
10. Add the IP back to mon_host in /etc/ceph/ceph.conf
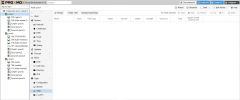
Now that this has all been done, my Ceph cluster is healthy and everything looks okay except for one thing. When I go to my re-imaged host and click Ceph->OSD, sometimes no OSD info comes up at all. If I hit reload, I get a spinning wheel for a few seconds and sometimes the OSDs show up and other times it still displays nothing. I'll attach a screenshot of this particular screen from the GUI. I have a feeling that there is some configuration that is still not quite right, but I am not sure which config that could be. Any ideas?
Thanks,
Stan
I recently upgraded the HBA in a Dell R720 with one that supports IT mode. This host was in a 3-node cluster with Ceph. When I booted after the HBA replacement, the rpool could not be imported, and I was taken to the initramfs prompt. Instead of just importing the rpool and then following this thread https://www.reddit.com/r/Proxmox/comments/fbdgos/cannot_import_rpool_automatically/ to just change the sleep values for ZFS_INITRD_PRE_MOUNTROOT_SLEEP and ZFS_INITRD_POST_MODPROBE_SLEEP in /etc/default/zfs, I decided to just reinstall Proxmox on the host. After reinstalling Proxmox on the host, I ran into the same issue at boot but was able to fix the issue by changing those sleep values. After configuring network settings and rejoining the cluster and following the instructions from this thread https://forum.proxmox.com/threads/reinstall-pve-node-with-ceph.59665/, I was able to get everything back up. Here is what I did:
1. Install Proxmox again
2. Recover networking settings (can be retrieved from another working node).
3. Make sure /etc/resolv.conf /etc/apt/sources /etc/hosts are all correct.
4. Join node to cluster (sometimes you will have to remove the failed node first. ie: pvecm rm nodename)
5. Install Ceph on the new node
6. Remove old failed node monitor.
- ceph mon rm nodename
- remove IP from mon_host in /etc/ceph/ceph.conf
7. Create monitor for new node - resource: https://docs.ceph.com/en/nautilus/rados/operations/add-or-rm-mons/
- follow steps for adding a monitor manually
- make sure that the /var/lib/ceph/mon/nodename directory is owned by the user ceph (because that is the user that the ceph monitor service runs as)
- monitor keyring can be retrieved from another working host at /etc/pve/priv/ceph.mon.keyring
- monitor map is retrieved by running: ceph mon getmap > monmap.file on a working host in the cluster.
- port number is not necessary on the last step: ceph-mon -i nodename --public-addr 172.16.1.xx
8. Run: ceph-volume lvm activate --all
9. In the Gui, go to the node->Ceph->OSD and click the OSD for the new node and then click the start button.
10. Add the IP back to mon_host in /etc/ceph/ceph.conf
Now that this has all been done, my Ceph cluster is healthy and everything looks okay except for one thing. When I go to my re-imaged host and click Ceph->OSD, sometimes no OSD info comes up at all. If I hit reload, I get a spinning wheel for a few seconds and sometimes the OSDs show up and other times it still displays nothing. I'll attach a screenshot of this particular screen from the GUI. I have a feeling that there is some configuration that is still not quite right, but I am not sure which config that could be. Any ideas?
Thanks,
Stan
Attachments
Last edited:
