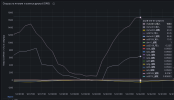
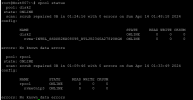
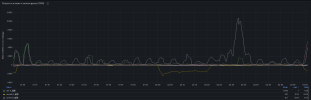
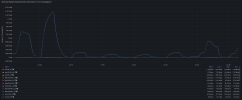
A lot of synchronization error messages come, mostly during non-working hours at night. One of hundreds of errors that come in the mail below.
Tell me what to do about this, we are afraid that at some point we will have broken copies on the server receiving replication.
Replication job 132-1 with target 'Host807' and schedule '*/5' failed!
Last successful sync: 2024-04-17 05:06:29
Next sync try: 2024-04-17 05:32:39
Failure count: 2
Error:
command 'zfs snapshot disk2/vm-132-disk-0@__replicate_132-1_1713320590__' failed: got timeout
Tell me what to do about this, we are afraid that at some point we will have broken copies on the server receiving replication.
Replication job 132-1 with target 'Host807' and schedule '*/5' failed!
Last successful sync: 2024-04-17 05:06:29
Next sync try: 2024-04-17 05:32:39
Failure count: 2
Error:
command 'zfs snapshot disk2/vm-132-disk-0@__replicate_132-1_1713320590__' failed: got timeout