Hello there!
I am coming to you following a concern that I have been encountering for several months already ...
In a little blocking environment, until now, I have postponed the treatment by restarting the machine.
I manage a standalone server installed natively in ZFS.
The server has 64G of RAM and an i7 7700K core.
When the server has been running for four or five days, I end up:
- lose access to the web interface,
- My host OS seems to accept some Inputs, but not all, and overall refuses to write to the / etc directory
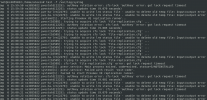
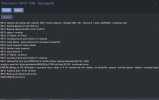
At this point, and from that point on, my syslog file starts to look like the attached file "bug_IO_srv.png".
I have already used the pve update-tools, and configured internal clock on UTC...
I have now really no idea how i can solve them ... Any idea is welcome")
I am coming to you following a concern that I have been encountering for several months already ...
In a little blocking environment, until now, I have postponed the treatment by restarting the machine.
I manage a standalone server installed natively in ZFS.
The server has 64G of RAM and an i7 7700K core.
When the server has been running for four or five days, I end up:
- lose access to the web interface,
- My host OS seems to accept some Inputs, but not all, and overall refuses to write to the / etc directory
At this point, and from that point on, my syslog file starts to look like the attached file "bug_IO_srv.png".
I have already used the pve update-tools, and configured internal clock on UTC...
I have now really no idea how i can solve them ... Any idea is welcome