[SOLVED] PVE Shutdown/Reboot takes more than 10 minutes
- Thread starter fpdragon
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.


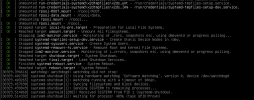
To find out which service takes a long time you may run
Logged errors since last boot should be shown by
~# systemd-analyze blame. See https://www.freedesktop.org/software/systemd/man/latest/systemd-analyze.html for other commands like "...time", "...critical-chain", ...Logged errors since last boot should be shown by
~# journalctl -b 0 -p 3
Thanks Udo.
Seems that there are several things goin on.
The firmware bug I read that this is something HW specific that linux wants to takeover some sensors. I guess it is non critical.
The quorum thing... before I had this machine running standalone and the shutdown took the same time.
/dev/sdf ... That was new to me. This is one of multiple disks that are passed through to a VM. SMART data is ok and the disk was working fine. At least I have not found an issue. Is the disk broken? Could this disk lead to the long shutdown delay and maybe also other problems?
What do you say?
Code:
~# journalctl -b 0 -p 3
Feb 05 11:20:06 ProxHpDL380 kernel: [Firmware Bug]: the BIOS has corrupted hw-PMU resources (MSR 38d is 330)
Feb 05 11:20:08 ProxHpDL380 kernel: i8042: Can't read CTR while initializing i8042
Feb 05 11:20:06 ProxHpDL380 systemd-modules-load[1293]: Failed to find module 'vfio_virqfd #not needed if on kernel 6.2 or newer'
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [quorum] crit: quorum_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [quorum] crit: can't initialize service
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [confdb] crit: cmap_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [confdb] crit: can't initialize service
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [dcdb] crit: cpg_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [dcdb] crit: can't initialize service
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [status] crit: cpg_initialize failed: 2
Feb 05 11:20:14 ProxHpDL380 pmxcfs[2740]: [status] crit: can't initialize service
Feb 05 11:20:18 ProxHpDL380 smartd[2420]: Device: /dev/sdf [SAT], 341 Currently unreadable (pending) sectors
Feb 05 11:20:18 ProxHpDL380 smartd[2420]: Device: /dev/sdf [SAT], 340 Offline uncorrectable sectors
Feb 05 11:20:28 ProxHpDL380 pve-guests[2994]: CT is locked (disk)Seems that there are several things goin on.
The firmware bug I read that this is something HW specific that linux wants to takeover some sensors. I guess it is non critical.
The quorum thing... before I had this machine running standalone and the shutdown took the same time.
/dev/sdf ... That was new to me. This is one of multiple disks that are passed through to a VM. SMART data is ok and the disk was working fine. At least I have not found an issue. Is the disk broken? Could this disk lead to the long shutdown delay and maybe also other problems?
What do you say?
I set /dev/sdf to "retired", rebuild my storage pool and removed it.
now the shutdown takes only seconds.
Thanks a lot for the help.
was the solution
now the shutdown takes only seconds.
Thanks a lot for the help.
Code:
~# journalctl -b 0 -p 3")