Sehr geehrte Community,
heute hatten wir ein merkwürdiges Phänomen, da ich wenig PVE Erfahrung habe könnt ihr mir da ggf. weiterhelfen.
Wir betreiben einen mehr oder minder unproduktiven PVE Host an einem Standort, der sich wie folgt aufbaut:
2x 250GB Sata SSDs Raid1 --> PVE OS
6x Sata SSD --> Raidz10 für VMs
10x 4TB HDDs --> Raidz10 Massenspeicher
Heute früh habe ich einer VM ein 8TB Laufwerk zugewiesen und diese auf dem Massenspeicherpool abgelegt.
Dann wurden Daten auf das 8TB Laufwerk übertragen.
Ab Mittag wurde dann der PVE Host instabil, es gab immer wieder kurze Aussetzer beim Versuch das WebUI zu bedienen oder sich per SSH zu verbinden.
Die 2 dort laufenden VMs waren ebenfalls immer wieder kurz unerreichbar.
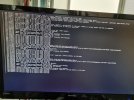
Ich hatte dann den PVE Host auf gut Glück einmal neugestartet, nur um dann ewig in einer schwarzen Maske zu hängen in der PVE mir immer wieder anzeigt das eine bestimmte Platte defekt sei. Siehe Anhang.
Soweit so gut...
Nach 20 Minuten war die Kiste dann wieder hochgefahren und das WebUI wieder erreichbar.
Die vormals defekte HDD wurde als Funktionierend und operabel angezeigt - Merkwürdig.
Aber nach 5 Minuten ging das gleiche Thema wieder von vorne los, das WebUI reagierte nicht mehr richtig usw.
Ich hab die HDD also physisch am Host entfernt und via zpool offline poolname HDD-ID offline gestellt.
Danach war alles wieder normal und blieb es auch.
Ich hatte eine passende 4TB HDD vor Ort, deshalb habe ich diese gleich via zpool replace ersetzt, seit dem läuft der Host auch wieder ganz normal.
Meine Fragen dazu wären die folgenden:
Warum führt der "Defekt" einer HDD eines zfspools der prinzipiell mit dem PVE Host OS nichts zu tun hat dazu, das das ganze System instabil wird?
Und zweitens, kann der Vorgang nicht theoretisch auch automatisiert erfolgen wenn ich die Festplatte physisch entferne und eine neue einsetze, wieso muss ich die Platte erst offline schalten und dann replacen via shell?
Mein Wunschszenario wäre das der Host normal funktioniert auch wenn eine HDD kaputt geht und das der resilvering Prozess automatisch passiert wenn die defekte Platte physisch ersetzt wurde.
Vielen Dank und viele Grüße,
pvenewbie
heute hatten wir ein merkwürdiges Phänomen, da ich wenig PVE Erfahrung habe könnt ihr mir da ggf. weiterhelfen.
Wir betreiben einen mehr oder minder unproduktiven PVE Host an einem Standort, der sich wie folgt aufbaut:
2x 250GB Sata SSDs Raid1 --> PVE OS
6x Sata SSD --> Raidz10 für VMs
10x 4TB HDDs --> Raidz10 Massenspeicher
Heute früh habe ich einer VM ein 8TB Laufwerk zugewiesen und diese auf dem Massenspeicherpool abgelegt.
Dann wurden Daten auf das 8TB Laufwerk übertragen.
Ab Mittag wurde dann der PVE Host instabil, es gab immer wieder kurze Aussetzer beim Versuch das WebUI zu bedienen oder sich per SSH zu verbinden.
Die 2 dort laufenden VMs waren ebenfalls immer wieder kurz unerreichbar.
Ich hatte dann den PVE Host auf gut Glück einmal neugestartet, nur um dann ewig in einer schwarzen Maske zu hängen in der PVE mir immer wieder anzeigt das eine bestimmte Platte defekt sei. Siehe Anhang.
Soweit so gut...
Nach 20 Minuten war die Kiste dann wieder hochgefahren und das WebUI wieder erreichbar.
Die vormals defekte HDD wurde als Funktionierend und operabel angezeigt - Merkwürdig.
Aber nach 5 Minuten ging das gleiche Thema wieder von vorne los, das WebUI reagierte nicht mehr richtig usw.
Ich hab die HDD also physisch am Host entfernt und via zpool offline poolname HDD-ID offline gestellt.
Danach war alles wieder normal und blieb es auch.
Ich hatte eine passende 4TB HDD vor Ort, deshalb habe ich diese gleich via zpool replace ersetzt, seit dem läuft der Host auch wieder ganz normal.
Meine Fragen dazu wären die folgenden:
Warum führt der "Defekt" einer HDD eines zfspools der prinzipiell mit dem PVE Host OS nichts zu tun hat dazu, das das ganze System instabil wird?
Und zweitens, kann der Vorgang nicht theoretisch auch automatisiert erfolgen wenn ich die Festplatte physisch entferne und eine neue einsetze, wieso muss ich die Platte erst offline schalten und dann replacen via shell?
Mein Wunschszenario wäre das der Host normal funktioniert auch wenn eine HDD kaputt geht und das der resilvering Prozess automatisch passiert wenn die defekte Platte physisch ersetzt wurde.
Vielen Dank und viele Grüße,
pvenewbie
")
