Hallo Gemeinde,
ich weiß leider nicht mehr weiter.
Mein PVE friert für mich ohne Fehlermeldung nach einigen Tagen oder Wochen einfach ein.
Das System läuft auf einen DELL Optiplex 3050MICO I5-6500T/32GB RAM. EINE M2 SSD 1TB und eine 2TB SSD als SSATA als Datenplatte.
Vielleicht kann einer von euch mal durch meinen Journal schauen und kann mir einen Tipp geben.
Das System lief bis gestern ca. 21Uhr.
Anschließend:
Neustart 16:27 13.10.2024
Letzte Neustart 11.09. 11:05
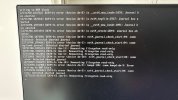
Ich habe noch ein Bild von dem ersten Crash im Sept. angehangen.
Da hatte ich ein Bildschirm angeschlossen, was ich jetzt leider nicht gemacht habe.
pveversion -v:
proxmox-ve: 8.2.0 (running kernel: 6.8.4-2-pve)
pve-manager: 8.2.2 (running version: 8.2.2/9355359cd7afbae4)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.4-2
proxmox-kernel-6.8.4-2-pve-signed: 6.8.4-2
ceph-fuse: 17.2.7-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx8
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-4
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.0
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.3
libpve-access-control: 8.1.4
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.6
libpve-cluster-perl: 8.0.6
libpve-common-perl: 8.2.1
libpve-guest-common-perl: 5.1.1
libpve-http-server-perl: 5.1.0
libpve-network-perl: 0.9.8
libpve-rs-perl: 0.8.8
libpve-storage-perl: 8.2.1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.4.0-3
proxmox-backup-client: 3.2.0-1
proxmox-backup-file-restore: 3.2.0-1
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.2.3
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.6
proxmox-widget-toolkit: 4.2.1
pve-cluster: 8.0.6
pve-container: 5.0.10
pve-docs: 8.2.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.0
pve-firewall: 5.0.5
pve-firmware: 3.11-1
pve-ha-manager: 4.0.4
pve-i18n: 3.2.2
pve-qemu-kvm: 8.1.5-5
pve-xtermjs: 5.3.0-3
qemu-server: 8.2.1
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.3-pve2
root@Datacenter:~# lspci -nnk
00:00.0 Host bridge [0600]: Intel Corporation Xeon E3-1200 v6/7th Gen Core Processor Host Bridge/DRAM Registers [8086:591f] (rev 05)
Subsystem: Dell Xeon E3-1200 v6/7th Gen Core Processor Host Bridge/DRAM Registers [1028:07a3]
Kernel driver in use: skl_uncore
00:02.0 VGA compatible controller [0300]: Intel Corporation HD Graphics 630 [8086:5912] (rev 04)
Subsystem: Dell HD Graphics 630 [1028:07a3]
Kernel driver in use: i915
Kernel modules: i915
00:14.0 USB controller [0c03]: Intel Corporation 200 Series/Z370 Chipset Family USB 3.0 xHCI Controller [8086:a2af]
Subsystem: Dell 200 Series/Z370 Chipset Family USB 3.0 xHCI Controller [1028:07a3]
Kernel driver in use: xhci_hcd
Kernel modules: xhci_pci
00:14.2 Signal processing controller [1180]: Intel Corporation 200 Series PCH Thermal Subsystem [8086:a2b1]
Subsystem: Dell 200 Series PCH Thermal Subsystem [1028:07a3]
00:16.0 Communication controller [0780]: Intel Corporation 200 Series PCH CSME HECI #1 [8086:a2ba]
Subsystem: Dell 200 Series PCH CSME HECI [1028:07a3]
Kernel driver in use: mei_me
Kernel modules: mei_me
00:17.0 SATA controller [0106]: Intel Corporation 200 Series PCH SATA controller [AHCI mode] [8086:a282]
Subsystem: Dell 200 Series PCH SATA controller [AHCI mode] [1028:07a3]
Kernel driver in use: ahci
Kernel modules: ahci
00:1b.0 PCI bridge [0604]: Intel Corporation 200 Series PCH PCI Express Root Port #21 [8086:a2eb] (rev f0)
Kernel driver in use: pcieport
00:1c.0 PCI bridge [0604]: Intel Corporation 200 Series PCH PCI Express Root Port #5 [8086:a294] (rev f0)
Subsystem: Dell 200 Series PCH PCI Express Root Port [1028:07a3]
Kernel driver in use: pcieport
00:1c.7 PCI bridge [0604]: Intel Corporation 200 Series PCH PCI Express Root Port #8 [8086:a297] (rev f0)
Subsystem: Dell 200 Series PCH PCI Express Root Port [1028:07a3]
Kernel driver in use: pcieport
00:1f.0 ISA bridge [0601]: Intel Corporation 200 Series PCH LPC Controller (B250) [8086:a2c8]
Subsystem: Dell 200 Series PCH LPC Controller (B250) [1028:07a3]
00:1f.2 Memory controller [0580]: Intel Corporation 200 Series/Z370 Chipset Family Power Management Controller [8086:a2a1]
Subsystem: Dell 200 Series/Z370 Chipset Family Power Management Controller [1028:07a3]
00:1f.3 Audio device [0403]: Intel Corporation 200 Series PCH HD Audio [8086:a2f0]
Subsystem: Dell 200 Series PCH HD Audio [1028:07a3]
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel, snd_soc_avs
00:1f.4 SMBus [0c05]: Intel Corporation 200 Series/Z370 Chipset Family SMBus Controller [8086:a2a3]
Subsystem: Dell 200 Series/Z370 Chipset Family SMBus Controller [1028:07a3]
Kernel driver in use: i801_smbus
Kernel modules: i2c_i801
01:00.0 Non-Volatile memory controller [0108]: Sandisk Corp WD Black SN750 / PC SN730 NVMe SSD [15b7:5006]
Subsystem: Sandisk Corp SanDisk Extreme Pro / WD Black SN750 / PC SN730 / Red SN700 NVMe SSD [15b7:5006]
Kernel driver in use: nvme
Kernel modules: nvme
02:00.0 Ethernet controller [0200]: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller [10ec:8168] (rev 15)
Subsystem: Dell RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller [1028:07a3]
Kernel driver in use: r8169
Kernel modules: r8169
03:00.0 Network controller [0280]: Intel Corporation Wireless 3165 [8086:3165] (rev 79)
Subsystem: Intel Corporation Wireless 3165 [8086:4410]
Kernel driver in use: iwlwifi
Kernel modules: iwlwifi
ich weiß leider nicht mehr weiter.
Mein PVE friert für mich ohne Fehlermeldung nach einigen Tagen oder Wochen einfach ein.
Das System läuft auf einen DELL Optiplex 3050MICO I5-6500T/32GB RAM. EINE M2 SSD 1TB und eine 2TB SSD als SSATA als Datenplatte.
Vielleicht kann einer von euch mal durch meinen Journal schauen und kann mir einen Tipp geben.
Das System lief bis gestern ca. 21Uhr.
Anschließend:
- Kein PING
- Kein SSH
- Keine WEB GUI
- VMs und LXCs nicht erreichbar
Neustart 16:27 13.10.2024
Letzte Neustart 11.09. 11:05
Ich habe noch ein Bild von dem ersten Crash im Sept. angehangen.
Da hatte ich ein Bildschirm angeschlossen, was ich jetzt leider nicht gemacht habe.
pveversion -v:
proxmox-ve: 8.2.0 (running kernel: 6.8.4-2-pve)
pve-manager: 8.2.2 (running version: 8.2.2/9355359cd7afbae4)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.4-2
proxmox-kernel-6.8.4-2-pve-signed: 6.8.4-2
ceph-fuse: 17.2.7-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx8
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-4
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.0
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.3
libpve-access-control: 8.1.4
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.6
libpve-cluster-perl: 8.0.6
libpve-common-perl: 8.2.1
libpve-guest-common-perl: 5.1.1
libpve-http-server-perl: 5.1.0
libpve-network-perl: 0.9.8
libpve-rs-perl: 0.8.8
libpve-storage-perl: 8.2.1
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.4.0-3
proxmox-backup-client: 3.2.0-1
proxmox-backup-file-restore: 3.2.0-1
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.2.3
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.6
proxmox-widget-toolkit: 4.2.1
pve-cluster: 8.0.6
pve-container: 5.0.10
pve-docs: 8.2.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.0
pve-firewall: 5.0.5
pve-firmware: 3.11-1
pve-ha-manager: 4.0.4
pve-i18n: 3.2.2
pve-qemu-kvm: 8.1.5-5
pve-xtermjs: 5.3.0-3
qemu-server: 8.2.1
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.3-pve2
root@Datacenter:~# lspci -nnk
00:00.0 Host bridge [0600]: Intel Corporation Xeon E3-1200 v6/7th Gen Core Processor Host Bridge/DRAM Registers [8086:591f] (rev 05)
Subsystem: Dell Xeon E3-1200 v6/7th Gen Core Processor Host Bridge/DRAM Registers [1028:07a3]
Kernel driver in use: skl_uncore
00:02.0 VGA compatible controller [0300]: Intel Corporation HD Graphics 630 [8086:5912] (rev 04)
Subsystem: Dell HD Graphics 630 [1028:07a3]
Kernel driver in use: i915
Kernel modules: i915
00:14.0 USB controller [0c03]: Intel Corporation 200 Series/Z370 Chipset Family USB 3.0 xHCI Controller [8086:a2af]
Subsystem: Dell 200 Series/Z370 Chipset Family USB 3.0 xHCI Controller [1028:07a3]
Kernel driver in use: xhci_hcd
Kernel modules: xhci_pci
00:14.2 Signal processing controller [1180]: Intel Corporation 200 Series PCH Thermal Subsystem [8086:a2b1]
Subsystem: Dell 200 Series PCH Thermal Subsystem [1028:07a3]
00:16.0 Communication controller [0780]: Intel Corporation 200 Series PCH CSME HECI #1 [8086:a2ba]
Subsystem: Dell 200 Series PCH CSME HECI [1028:07a3]
Kernel driver in use: mei_me
Kernel modules: mei_me
00:17.0 SATA controller [0106]: Intel Corporation 200 Series PCH SATA controller [AHCI mode] [8086:a282]
Subsystem: Dell 200 Series PCH SATA controller [AHCI mode] [1028:07a3]
Kernel driver in use: ahci
Kernel modules: ahci
00:1b.0 PCI bridge [0604]: Intel Corporation 200 Series PCH PCI Express Root Port #21 [8086:a2eb] (rev f0)
Kernel driver in use: pcieport
00:1c.0 PCI bridge [0604]: Intel Corporation 200 Series PCH PCI Express Root Port #5 [8086:a294] (rev f0)
Subsystem: Dell 200 Series PCH PCI Express Root Port [1028:07a3]
Kernel driver in use: pcieport
00:1c.7 PCI bridge [0604]: Intel Corporation 200 Series PCH PCI Express Root Port #8 [8086:a297] (rev f0)
Subsystem: Dell 200 Series PCH PCI Express Root Port [1028:07a3]
Kernel driver in use: pcieport
00:1f.0 ISA bridge [0601]: Intel Corporation 200 Series PCH LPC Controller (B250) [8086:a2c8]
Subsystem: Dell 200 Series PCH LPC Controller (B250) [1028:07a3]
00:1f.2 Memory controller [0580]: Intel Corporation 200 Series/Z370 Chipset Family Power Management Controller [8086:a2a1]
Subsystem: Dell 200 Series/Z370 Chipset Family Power Management Controller [1028:07a3]
00:1f.3 Audio device [0403]: Intel Corporation 200 Series PCH HD Audio [8086:a2f0]
Subsystem: Dell 200 Series PCH HD Audio [1028:07a3]
Kernel driver in use: snd_hda_intel
Kernel modules: snd_hda_intel, snd_soc_avs
00:1f.4 SMBus [0c05]: Intel Corporation 200 Series/Z370 Chipset Family SMBus Controller [8086:a2a3]
Subsystem: Dell 200 Series/Z370 Chipset Family SMBus Controller [1028:07a3]
Kernel driver in use: i801_smbus
Kernel modules: i2c_i801
01:00.0 Non-Volatile memory controller [0108]: Sandisk Corp WD Black SN750 / PC SN730 NVMe SSD [15b7:5006]
Subsystem: Sandisk Corp SanDisk Extreme Pro / WD Black SN750 / PC SN730 / Red SN700 NVMe SSD [15b7:5006]
Kernel driver in use: nvme
Kernel modules: nvme
02:00.0 Ethernet controller [0200]: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller [10ec:8168] (rev 15)
Subsystem: Dell RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller [1028:07a3]
Kernel driver in use: r8169
Kernel modules: r8169
03:00.0 Network controller [0280]: Intel Corporation Wireless 3165 [8086:3165] (rev 79)
Subsystem: Intel Corporation Wireless 3165 [8086:4410]
Kernel driver in use: iwlwifi
Kernel modules: iwlwifi
Attachments
Last edited: