Please post the full output ofI did a test on one production server with the correct setup for CEPH (no hardware RAID).
Upgraded from PVE 7.4-18 to PVE 8.2.4.
We also have Debian 12 LXC's and with HA migration to the node with the latest version of PVE, it doesn't want to start.
I tested with a Debian LXC with id 102:
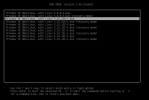
Bash:task started by HA resource agent run_buffer: 571 Script exited with status 255 lxc_init: 845 Failed to run lxc.hook.pre-start for container "101" __lxc_start: 2034 Failed to initialize container "101" TASK ERROR: startup for container '101' failed
Journalctl -xe mentions a ext4 error:
Bash:pve1# journalctl -xe Jul 16 10:42:11 pve1 kernel: loop0: detected capacity change from 0 to 20971520 Jul 16 10:42:11 pve1 kernel: EXT4-fs error (device loop0): ext4_get_journal_inode:5779: inode #8: comm mount: iget: checksum invalid Jul 16 10:42:11 pve1 kernel: EXT4-fs (loop0): no journal found Jul 16 10:42:11 pve1 kernel: I/O error, dev loop0, sector 20971392 op 0x0:(READ) flags 0x80700 phys_seg 1 prio class 0 Jul 16 10:42:11 pve1 pvedaemon[2135]: unable to get PID for CT 101 (not running?) Jul 16 10:42:11 pve1 pve-ha-lrm[32154]: startup for container '101' failed Jul 16 10:42:11 pve1 pve-ha-lrm[32152]: <root@pam> end task UPID:pve1:00007D9A:00015395:66963261:vzstart:101:root@pam: startup for container '101' failed Jul 16 10:42:11 pve1 pve-ha-lrm[32152]: unable to start service ct:101 Jul 16 10:42:11 pve1 pve-ha-lrm[4461]: restart policy: retry number 2 for service 'ct:101' Jul 16 10:42:13 pve1 systemd[1]: pve-container@101.service: Main process exited, code=exited, status=1/FAILURE
The configuration of the LCX:
Bash:# pct config 101 --current arch: amd64 cores: 1 description: # Vaultwarden LXC general%0A## Network config%0A| NIC | IPv4 | MAC | %0A| ---%3A--- | ---%3A--- | ---%3A--- |%0A| net0 | 192.168.16.101 | E2%3A61%3ADC%3A07%3A1F%3A8F |%0A features: keyctl=1,nesting=1 hostname: vaultwarden.internal.robotronic.be memory: 512 nameserver: 192.168.16.238 net0: name=eth0,bridge=vmbr0,gw=192.168.23.254,hwaddr=E2:61:DC:07:1F:8F,ip=192.168.16.101/21,type=veth onboot: 1 ostype: debian rootfs: vm-lxc-storage:101/vm-101-disk-0.raw,size=10G searchdomain: internal.robotronic.be swap: 512 tags: debian12;webserver unprivileged: 1
I ran a file system check on the LXC disk:
Bash:pve1# pct fsck 101 fsck from util-linux 2.38.1 /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw: Superblock has an invalid journal (inode 8). CLEARED. *** journal has been deleted *** /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw: Resize inode not valid. /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY. (i.e., without -a or -p options) command 'fsck -a -l /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw' failed: exit code 4
Then I ran it manually on the lxc disk (a lot of inode issues):
Bash:pve1# fsck -l /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw Inode 146317 ref count is 2, should be 1. Fix? yes Unattached inode 146319 Connect to /lost+found? yes /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw: ***** FILE SYSTEM WAS MODIFIED ***** /mnt/pve/cephfs_cluster/vm-lxc-storage/images/101/vm-101-disk-0.raw: 31726/655360 files (0.4% non-contiguous), 608611/2621440 blocks
I tried to startup the LXC in debug mode:
Bash:# pct start 101 --debug mount_autodev: 1028 Permission denied - Failed to create "/dev" directory lxc_setup: 3898 Failed to mount "/dev" do_start: 1273 Failed to setup container "101" sync_wait: 34 An error occurred in another process (expected sequence number 3) __lxc_start: 2114 Failed to spawn container "101" INFO utils - ../src/lxc/utils.c:run_script_argv:587 - Executing script "/usr/share/lxc/hooks/lxc-pve-prestart-hook" for container "101", config section "lxc" DEBUG utils - ../src/lxc/utils.c:run_buffer:560 - Script exec /usr/share/lxc/hooks/lxc-pve-prestart-hook 101 lxc pre-start produced output: /etc/os-release file not found and autodetection failed, falling back to 'unmanaged' WARNING: /etc not present in CT, is the rootfs mounted? got unexpected ostype (unmanaged != debian) INFO cgfsng - ../src/lxc/cgroups/cgfsng.c:unpriv_systemd_create_scope:1498 - Running privileged, not using a systemd unit DEBUG seccomp - ../src/lxc/seccomp.c:parse_config_v2:664 - Host native arch is [3221225534] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "reject_force_umount # comment this to allow umount -f; not recommended" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:532 - Set seccomp rule to reject force umounts INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:532 - Set seccomp rule to reject force umounts INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:532 - Set seccomp rule to reject force umounts INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "[all]" INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "kexec_load errno 1" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding native rule for syscall[246:kexec_load] action[327681:errno] arch[0] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[246:kexec_load] action[327681:errno] arch[1073741827] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[246:kexec_load] action[327681:errno] arch[1073741886] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "open_by_handle_at errno 1" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding native rule for syscall[304:open_by_handle_at] action[327681:errno] arch[0] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[304:open_by_handle_at] action[327681:errno] arch[1073741827] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[304:open_by_handle_at] action[327681:errno] arch[1073741886] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "init_module errno 1" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding native rule for syscall[175:init_module] action[327681:errno] arch[0] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[175:init_module] action[327681:errno] arch[1073741827] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[175:init_module] action[327681:errno] arch[1073741886] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "finit_module errno 1" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding native rule for syscall[313:finit_module] action[327681:errno] arch[0] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[313:finit_module] action[327681:errno] arch[1073741827] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[313:finit_module] action[327681:errno] arch[1073741886] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "delete_module errno 1" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding native rule for syscall[176:delete_module] action[327681:errno] arch[0] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[176:delete_module] action[327681:errno] arch[1073741827] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[176:delete_module] action[327681:errno] arch[1073741886] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:815 - Processing "ioctl errno 1 [1,0x9400,SCMP_CMP_MASKED_EQ,0xff00]" INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:555 - arg_cmp[0]: SCMP_CMP(1, 7, 65280, 37888) INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding native rule for syscall[16:ioctl] action[327681:errno] arch[0] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:555 - arg_cmp[0]: SCMP_CMP(1, 7, 65280, 37888) INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[16:ioctl] action[327681:errno] arch[1073741827] INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:555 - arg_cmp[0]: SCMP_CMP(1, 7, 65280, 37888) INFO seccomp - ../src/lxc/seccomp.c:do_resolve_add_rule:572 - Adding compat rule for syscall[16:ioctl] action[327681:errno] arch[1073741886] INFO seccomp - ../src/lxc/seccomp.c:parse_config_v2:1036 - Merging compat seccomp contexts into main context INFO start - ../src/lxc/start.c:lxc_init:882 - Container "101" is initialized INFO cgfsng - ../src/lxc/cgroups/cgfsng.c:cgfsng_monitor_create:1669 - The monitor process uses "lxc.monitor/101" as cgroup DEBUG storage - ../src/lxc/storage/storage.c:storage_query:231 - Detected rootfs type "dir" DEBUG storage - ../src/lxc/storage/storage.c:storage_query:231 - Detected rootfs type "dir" INFO cgfsng - ../src/lxc/cgroups/cgfsng.c:cgfsng_payload_create:1777 - The container process uses "lxc/101/ns" as inner and "lxc/101" as limit cgroup INFO start - ../src/lxc/start.c:lxc_spawn:1769 - Cloned CLONE_NEWUSER INFO start - ../src/lxc/start.c:lxc_spawn:1769 - Cloned CLONE_NEWNS INFO start - ../src/lxc/start.c:lxc_spawn:1769 - Cloned CLONE_NEWPID INFO start - ../src/lxc/start.c:lxc_spawn:1769 - Cloned CLONE_NEWUTS INFO start - ../src/lxc/start.c:lxc_spawn:1769 - Cloned CLONE_NEWIPC INFO start - ../src/lxc/start.c:lxc_spawn:1769 - Cloned CLONE_NEWCGROUP DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved user namespace via fd 17 and stashed path as user:/proc/37044/fd/17 DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved mnt namespace via fd 18 and stashed path as mnt:/proc/37044/fd/18 DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved pid namespace via fd 19 and stashed path as pid:/proc/37044/fd/19 DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved uts namespace via fd 20 and stashed path as uts:/proc/37044/fd/20 DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved ipc namespace via fd 21 and stashed path as ipc:/proc/37044/fd/21 DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved cgroup namespace via fd 22 and stashed path as cgroup:/proc/37044/fd/22 DEBUG idmap_utils - ../src/lxc/idmap_utils.c:idmaptool_on_path_and_privileged:93 - The binary "/usr/bin/newuidmap" does have the setuid bit set DEBUG idmap_utils - ../src/lxc/idmap_utils.c:idmaptool_on_path_and_privileged:93 - The binary "/usr/bin/newgidmap" does have the setuid bit set DEBUG idmap_utils - ../src/lxc/idmap_utils.c:lxc_map_ids:178 - Functional newuidmap and newgidmap binary found INFO cgfsng - ../src/lxc/cgroups/cgfsng.c:cgfsng_setup_limits:3528 - Limits for the unified cgroup hierarchy have been setup DEBUG idmap_utils - ../src/lxc/idmap_utils.c:idmaptool_on_path_and_privileged:93 - The binary "/usr/bin/newuidmap" does have the setuid bit set DEBUG idmap_utils - ../src/lxc/idmap_utils.c:idmaptool_on_path_and_privileged:93 - The binary "/usr/bin/newgidmap" does have the setuid bit set INFO idmap_utils - ../src/lxc/idmap_utils.c:lxc_map_ids:176 - Caller maps host root. Writing mapping directly NOTICE utils - ../src/lxc/utils.c:lxc_drop_groups:1572 - Dropped supplimentary groups INFO start - ../src/lxc/start.c:do_start:1105 - Unshared CLONE_NEWNET NOTICE utils - ../src/lxc/utils.c:lxc_drop_groups:1572 - Dropped supplimentary groups NOTICE utils - ../src/lxc/utils.c:lxc_switch_uid_gid:1548 - Switched to gid 0 NOTICE utils - ../src/lxc/utils.c:lxc_switch_uid_gid:1557 - Switched to uid 0 DEBUG start - ../src/lxc/start.c:lxc_try_preserve_namespace:140 - Preserved net namespace via fd 5 and stashed path as net:/proc/37044/fd/5 INFO utils - ../src/lxc/utils.c:run_script_argv:587 - Executing script "/usr/share/lxc/lxcnetaddbr" for container "101", config section "net" DEBUG network - ../src/lxc/network.c:netdev_configure_server_veth:876 - Instantiated veth tunnel "veth101i0 <--> vethgd6BVY" DEBUG conf - ../src/lxc/conf.c:lxc_mount_rootfs:1240 - Mounted rootfs "/var/lib/lxc/101/rootfs" onto "/usr/lib/x86_64-linux-gnu/lxc/rootfs" with options "(null)" INFO conf - ../src/lxc/conf.c:setup_utsname:679 - Set hostname to "vaultwarden.internal.robotronic.be" DEBUG network - ../src/lxc/network.c:setup_hw_addr:3863 - Mac address "E2:61:DC:07:1F:8F" on "eth0" has been setup DEBUG network - ../src/lxc/network.c:lxc_network_setup_in_child_namespaces_common:4004 - Network device "eth0" has been setup INFO network - ../src/lxc/network.c:lxc_setup_network_in_child_namespaces:4061 - Finished setting up network devices with caller assigned names INFO conf - ../src/lxc/conf.c:mount_autodev:1023 - Preparing "/dev" ERROR conf - ../src/lxc/conf.c:mount_autodev:1028 - Permission denied - Failed to create "/dev" directory INFO conf - ../src/lxc/conf.c:mount_autodev:1084 - Prepared "/dev" ERROR conf - ../src/lxc/conf.c:lxc_setup:3898 - Failed to mount "/dev" ERROR start - ../src/lxc/start.c:do_start:1273 - Failed to setup container "101" ERROR sync - ../src/lxc/sync.c:sync_wait:34 - An error occurred in another process (expected sequence number 3) DEBUG network - ../src/lxc/network.c:lxc_delete_network:4217 - Deleted network devices ERROR start - ../src/lxc/start.c:__lxc_start:2114 - Failed to spawn container "101" WARN start - ../src/lxc/start.c:lxc_abort:1037 - No such process - Failed to send SIGKILL via pidfd 16 for process 37080 startup for container '101' failed
When migrating the container back to another PVE node with version of 7.4-18 I now have the following error:
Bash:task started by HA resource agent mount_autodev: 1225 Permission denied - Failed to create "/dev" directory lxc_setup: 4395 Failed to mount "/dev" do_start: 1272 Failed to setup container "101" sync_wait: 34 An error occurred in another process (expected sequence number 3) __lxc_start: 2107 Failed to spawn container "101" TASK ERROR: startup for container '101' failed
Any idea's?
I want to update the whole production cluster only if I'm 100% sure that the containers can run on the latest PVE version...
Thank you for further investigating this!
pveversion -v for the node upgraded to PVE8 in code tags.Also, try to restore the container from backup to a different node (running PVE7) and only migrate it to the PVE8 node when that is booted into an older kernel version, does the issue persist in that case? Further, try to use the latest 6.8.8 kernel on the PVE8 host and also check if the container filesystem seems corrupted.
Also, if possible migrate the container from the CephFS backed storage to a different shared storage and see if the issue persists (again, with a container restored from backup onto a working PVE7 node).
")