I just ran a comparison with the benchmark running on just 1 node, and then the benchmark running on all 4 nodes to simulate heavy workloads across the entire cluster. Not only did the average IOPS drop as you'd expect, but the average latency jumped due to queueing.
I hope that using 40G will provide each node with enough bandwidth so that we don't don't see contention on the fabric. That should let each node run heavily loaded without degrading storage performance. I should have the hardware tomorrow so I'll post the results early next week.
David
...
Code:
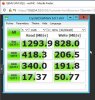
1 x bench over 10GbE
Max bandwidth (MB/sec): 1476
Min bandwidth (MB/sec): 1280
Average IOPS: 344
Stddev IOPS: 9.61719
Max IOPS: 369
Min IOPS: 320
Average Latency(s): 0.0463861
Code:
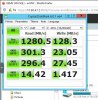
4 x bench over 10GbE
Max bandwidth (MB/sec): 1412
Min bandwidth (MB/sec): 412
Average IOPS: 132
Stddev IOPS: 38.3574
Max IOPS: 353
Min IOPS: 103
Average Latency(s): 0.120387I hope that using 40G will provide each node with enough bandwidth so that we don't don't see contention on the fabric. That should let each node run heavily loaded without degrading storage performance. I should have the hardware tomorrow so I'll post the results early next week.
David
...



")
 ) with a) about 200 MB/s and b) about 350 MB/s.
) with a) about 200 MB/s and b) about 350 MB/s.



