FWIK if disk is raw preallocated should be 13tb from start and not grow, if not preallocated it grows over time and to make it free up unused space you need to use discard/trim.
But it seems strange to me that it grows beyond the limit on raw format, the only ones I've seen grow beyond the maximum size are the qcow2 with internal snapshots.
Try to check with
Code:
qemu-img info <path of vm disk0>
In any case, I think that disk configuration in vm disk I think should be improved.
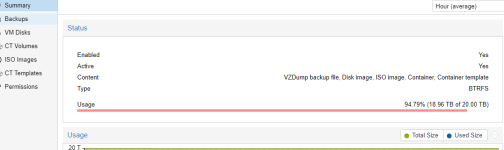
In the meantime, I hope you at least did the balance to avoid errors for full space (to deallocate free space) on btrfs volume.
EDIT:
I did a fast test creating a test vm inside latest proxmox I'm preparing for production on btrfs storage that I will use to store iso and templates to see if there are bugs in proxmox, but I didn't find, here are some details:
vm disk size before start, by default I saw that create it not preallocated, so is zero and taken also the usage of btrfs volume
Code:
qemu-img info /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
image: /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
file format: raw
virtual size: 50 GiB (53687091200 bytes)
disk size: 0 B
Child node '/file':
filename: /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
protocol type: file
file length: 50 GiB (53687091200 bytes)
disk size: 0 B
btrfs fi usage /mnt/nvme-data/
Overall:
Device size: 300.00GiB
Device allocated: 5.02GiB
Device unallocated: 294.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 1.22GiB
Free (estimated): 296.77GiB (min: 149.28GiB)
Free (statfs, df): 296.77GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 5.50MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:3.01GiB, Used:1.21GiB (40.36%)
/dev/mapper/nvme-data 3.01GiB
Metadata,DUP: Size:1.00GiB, Used:1.62MiB (0.16%)
/dev/mapper/nvme-data 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/mapper/nvme-data 16.00MiB
Unallocated:
/dev/mapper/nvme-data 294.98GiB
inside the vm formatted the disk as ext4 and created a file of 10gb
Code:
qemu-img info /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
image: /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
file format: raw
virtual size: 50 GiB (53687091200 bytes)
disk size: 10.5 GiB
Child node '/file':
filename: /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
protocol type: file
file length: 50 GiB (53687091200 bytes)
disk size: 10.5 GiB
btrfs fi usage /mnt/nvme-data/
Overall:
Device size: 300.00GiB
Device allocated: 16.02GiB
Device unallocated: 283.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 11.96GiB
Free (estimated): 286.04GiB (min: 144.06GiB)
Free (statfs, df): 286.04GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 11.53MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:14.01GiB, Used:11.94GiB (85.23%)
/dev/mapper/nvme-data 14.01GiB
Metadata,DUP: Size:1.00GiB, Used:11.73MiB (1.15%)
/dev/mapper/nvme-data 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/mapper/nvme-data 16.00MiB
Unallocated:
/dev/mapper/nvme-data 283.98GiB
after I deleted the file of 10gb in the vm and did fstrim, vm disk image decrease and also allocation on btrfs on proxmox
Code:
qemu-img info /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
image: /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
file format: raw
virtual size: 50 GiB (53687091200 bytes)
disk size: 1.04 GiB
Child node '/file':
filename: /mnt/nvme-data/images/100/vm-100-disk-0/disk.raw
protocol type: file
file length: 50 GiB (53687091200 bytes)
disk size: 1.04 GiB
btrfs fi usage /mnt/nvme-data/
Overall:
Device size: 300.00GiB
Device allocated: 6.02GiB
Device unallocated: 293.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 2.25GiB
Free (estimated): 295.73GiB (min: 148.74GiB)
Free (statfs, df): 295.73GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 11.53MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:4.01GiB, Used:2.25GiB (56.18%)
/dev/mapper/nvme-data 4.01GiB
Metadata,DUP: Size:1.00GiB, Used:1.77MiB (0.17%)
/dev/mapper/nvme-data 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/mapper/nvme-data 16.00MiB
Unallocated:
/dev/mapper/nvme-data 293.98GiB
so I have not spotted bugs or unexpected case
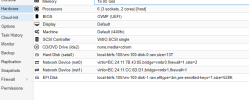
my test vm configuration is:
Code:
less /etc/pve/qemu-server/100.conf
agent: 1
balloon: 0
boot: order=scsi0;ide2;net0
cores: 4
cpu: host
ide2: nvme-data:iso/gparted-live-1.6.0-10-amd64.iso,media=cdrom,size=550M
memory: 8192
meta: creation-qemu=9.0.2,ctime=1732190472
name: test
net0: virtio=BC:24:11:85:BA:5B,bridge=vmbr0,firewall=1
numa: 0
ostype: l26
scsi0: nvme-data:100/vm-100-disk-0.raw,backup=0,discard=on,iothread=1,size=50G
scsihw: virtio-scsi-single
smbios1: uuid=64806fed-8b2c-4fc6-828b-235e60508ed2
sockets: 1
vmgenid: 7978b3c9-3ddf-4266-93a9-6767c0ce0d14
If you enable discard in vm disk and do a fstrim inside the vm I think should unallocate the free space of the vm disk, I suggest also to set disk as virtio scsi instead sata unless you use it for some special problem, I usually use ide or sata temporarily just for p2v vm windows
-----------------
EDIT2:
I did some another fast tests trying to exceed the disk limit, but I only exceeded it with snapshots, taking 2 snapshots and emptying and filling in the middle the vm disk.
What I saw is not a bug but normal (the important is need to do a good management), as I have seen there would be space management problems with the use of snapshots even with lvmthin and I suppose also with zfs.
These are not system problems, but management deficiencies that sysadmin or users do.
Here used space > total vm disk space because of snapshots and full disk rewrite in the middle
Code:
btrfs sub list /mnt/nvme-data/
ID 256 gen 153 top level 5 path images/100/vm-100-disk-0
ID 258 gen 100 top level 5 path images/100/vm-100-disk-0@snaptest1
ID 259 gen 126 top level 5 path images/100/vm-100-disk-0@snaptest2
btrfs fi usage /mnt/nvme-data/
Overall:
Device size: 300.00GiB
Device allocated: 85.02GiB
Device unallocated: 214.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 80.54GiB
Free (estimated): 217.60GiB (min: 110.11GiB)
Free (statfs, df): 217.60GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 81.06MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:83.01GiB, Used:80.38GiB (96.84%)
/dev/mapper/nvme-data 83.01GiB
Metadata,DUP: Size:1.00GiB, Used:81.94MiB (8.00%)
/dev/mapper/nvme-data 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/mapper/nvme-data 16.00MiB
Unallocated:
/dev/mapper/nvme-data 214.98GiB
And after delete of snapshot, remove the test files from vm disk, doing fstrim and waiting garbage collector to fully remove the snapshots returned normally and it turns out it has also freed up correctly on btrfs
Code:
btrfs fi usage /mnt/nvme-data/
Overall:
Device size: 300.00GiB
Device allocated: 6.02GiB
Device unallocated: 293.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 2.26GiB
Free (estimated): 295.73GiB (min: 148.74GiB)
Free (statfs, df): 295.72GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 81.06MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:4.01GiB, Used:2.26GiB (56.34%)
/dev/mapper/nvme-data 4.01GiB
Metadata,DUP: Size:1.00GiB, Used:1.83MiB (0.18%)
/dev/mapper/nvme-data 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/mapper/nvme-data 16.00MiB
Unallocated:
/dev/mapper/nvme-data 293.98GiB
I didn't find a bug but is normal, as I saw you would have space management problems with the use of snapshots even with lvmthin (and I suppose also with zfs) without a good management.
There are other cases when using not preallocated disk that can require more management.
These normally are not system problems but management mistake that sysadmin or users do.
However, I am curious to know in the case reported if once the VM configuration has been fixed and the necessary operations have been carried out, host disk usage returns to normal or if there is a real bug in the version used.
In fact on proxmox I have already found some regressions after updates, partly it is normal because on the systems where it happened to me I do not have a subscription (and therefore it is a bit like a "beta tester"), then being partially "rolling release" on different main components such as kernel and qemu I have seen more regressions compared to the use of debian stable to which I was used.
Regarding btrfs itself in proxmox its implementation still needs to be improved in some things, for example if someone wanted to take snapshots outside of vm disks would need to configure the subvolumes regarding the root to reduce possible space and performance problems.