This is the task viewer for one of the machines.....
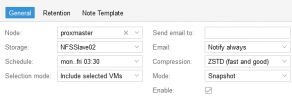
INFO: starting new backup job: vzdump 10224 --node proxmaster --quiet 1 --prune-backups 'keep-last=7' --compress zstd --mode snapshot --storage NFSSlave02 --mailnotification always
INFO: Starting Backup of VM 10224 (qemu)
INFO: Backup started at 2023-04-21 03:30:14
INFO: status = running
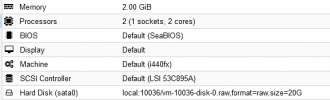
INFO: include disk 'sata0' 'local:10224/vm-10224-disk-0.raw' 20G
INFO: include disk 'sata1' 'local:10224/vm-10224-disk-1.raw' 35G
INFO: backup mode: snapshot
INFO: ionice priority: 7
INFO: creating vzdump archive '/mnt/pve/NFSSlave02/dump/vzdump-qemu-10224-2023_04_21-03_30_13.vma.zst'
INFO: started backup task '836dea1c-1e6e-4c36-8222-7c900f68a0bc'
INFO: resuming VM again
INFO: 0% (174.0 MiB of 55.0 GiB) in 3s, read: 58.0 MiB/s, write: 49.9 MiB/s
# didnt include all the percentages because it's pointless
INFO: 98% (53.9 GiB of 55.0 GiB) in 19m 24s, read: 48.3 MiB/s, write: 47.8 MiB/s
INFO: 99% (54.9 GiB of 55.0 GiB) in 19m 28s, read: 251.0 MiB/s, write: 45.3 MiB/s
INFO: 100% (55.0 GiB of 55.0 GiB) in 19m 29s, read: 99.9 MiB/s, write: 47.3 MiB/s
INFO: backup is sparse: 2.17 GiB (3%) total zero data
INFO: transferred 55.00 GiB in 1169 seconds (48.2 MiB/s)
INFO: archive file size: 18.31GB
INFO: prune older backups with retention: keep-last=7
INFO: removing backup 'NFSSlave02:backup/vzdump-qemu-10224-2023_04_12-03_30_00.vma.zst'
INFO: pruned 1 backup(s) not covered by keep-retention policy
INFO: Finished Backup of VM 10224 (00:19:32)
INFO: Backup finished at 2023-04-21 03:49:45
INFO: Backup job finished successfully
TASK OK
Logs from the cluster
Apr 21 03:30:14 proxmaster pvescheduler[3943208]: INFO: Starting Backup of VM 10224 (qemu)
Apr 21 03:39:21 proxmaster smartd[1278]: Device: /dev/sda [SAT], SMART Usage Attribute: 19
0 Airflow_Temperature_Cel changed from 65 to 67
Apr 21 03:39:21 proxmaster smartd[1278]: Device: /dev/sdb [SAT], SMART Usage Attribute: 194 Temperature_Celsius changed from 123 to 125
Apr 21 03:39:21 proxmaster smartd[1278]: Device: /dev/sdc [SAT], SMART Usage Attribute: 190 Airflow_Temperature_Cel changed from 64 to 65
Apr 21 03:46:49 proxmaster corosync[1782]: [KNET ] link: host: 3 link: 0 is down
Apr 21 03:46:49 proxmaster corosync[1782]: [KNET ] host: host: 3 (passive) best link: 0 (pri: 1)
Apr 21 03:46:49 proxmaster corosync[1782]: [KNET ] host: host: 3 has no active links
Apr 21 03:46:51 proxmaster corosync[1782]: [KNET ] rx: host: 3 link: 0 is up
Apr 21 03:46:51 proxmaster corosync[1782]: [KNET ] host: host: 3 (passive) best link: 0 (pri: 1)
Apr 21 03:46:52 proxmaster corosync[1782]: [TOTEM ] Token has not been received in 2737 ms
Apr 21 03:49:45 proxmaster pvescheduler[3943208]: INFO: Finished Backup of VM 10224 (00:19:32)
Apr 21 03:49:45 proxmaster pvescheduler[3943208]: INFO: Backup job finished successfully
Apr 21 04:00:02 proxmaster pmxcfs[1617]: [status] notice: received log
Apr 21 04:03:37 proxmaster kernel: Command line: BOOT_IMAGE=/boot/vmlinuz-5.15.39-2-pve root=UUID=51bb2a4e-3a36-47f4-9cf7-ee67b0a99f2c ro quiet
Apr 21 04:03:37 proxmaster kernel: KERNEL supported cpus:
Apr 21 04:03:37 proxmaster kernel: Kernel command line: BOOT_IMAGE=/boot/vmlinuz-5.15.39-2-pve root=UUID=51bb2a4e-3a36-47f4-9cf7-ee67b0a99f2c ro quiet
Apr 21 04:03:37 proxmaster kernel: Unknown kernel command line parameters "BOOT_IMAGE=/boot/vmlinuz-5.15.39-2-pve", will be passed to user space.
Apr 21 04:03:37 proxmaster kernel: sd 9:0:0:0: [sdf] Media removed, stopped polling
Apr 21 04:03:37 proxmaster kernel: sd 9:0:0:1: [sdg] Media removed, stopped polling
Apr 21 04:03:37 proxmaster kernel: sd 9:0:0:2: [sdh] Media removed, stopped polling
Apr 21 04:03:37 proxmaster kernel: sd 9:0:0:0: [sdf] Attached SCSI removable disk
Apr 21 04:03:37 proxmaster kernel: sd 9:0:0:1: [sdg] Attached SCSI removable disk
Apr 21 04:03:37 proxmaster kernel: sd 9:0:0:2: [sdh] Attached SCSI removable disk
Apr 21 04:03:37 proxmaster kernel: async_tx: api initialized (async)
Apr 21 04:03:37 proxmaster kernel: PM: Image not found (code -22)
Apr 21 04:03:37 proxmaster kernel: EXT4-fs (md126p1): mounted filesystem with ordered data mode. Opts: (null). Quota mode: none.
Apr 21 04:03:37 proxmaster systemd: Inserted module 'autofs4'
Apr 21 04:03:37 proxmaster systemd: systemd 247.3-7 running in system mode. (+PAM +AUDIT +SELINUX +IMA +APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 +ZSTD +SECCOMP +BLKID +ELFUTILS +KMOD +IDN2 -IDN +PCRE2 default-hierarchy=unified)
Apr 21 04:03:37 proxmaster systemd: Detected architecture x86-64.
Apr 21 04:03:37 proxmaster systemd: Set hostname to <proxmaster>.
Apr 21 04:03:37 proxmaster systemd: Queued start job for default target Graphical Interface.
Apr 21 04:03:37 proxmaster systemd: Created slice system-getty.slice.
Apr 21 04:03:37 proxmaster systemd: Created slice system-modprobe.slice.
Apr 21 04:03:37 proxmaster systemd: Created slice system-postfix.slice.
Apr 21 04:03:37 proxmaster systemd: Created slice system-zfs\x2dimport.slice.
Apr 21 04:03:37 proxmaster systemd: Created slice User and Session Slice.
Apr 21 04:03:37 proxmaster systemd: Started Dispatch Password Requests to Console Directory Watch.
Apr 21 04:03:37 proxmaster systemd: Started Forward Password Requests to Wall Directory Watch.
Apr 21 04:03:37 proxmaster systemd: Set up automount Arbitrary Executable File Formats File System Automount Point.
Apr 21 04:03:37 proxmaster systemd: Reached target ceph target allowing to start/stop all ceph-fuse@.service instances at once.
Apr 21 04:03:37 proxmaster systemd: Reached target ceph target allowing to start/stop all ceph*@.service instances at once.
Apr 21 04:03:37 proxmaster systemd: Reached target Local Encrypted Volumes.
Apr 21 04:03:37 proxmaster systemd: Reached target Paths.
Apr 21 04:03:37 proxmaster systemd: Reached target Slices.
Apr 21 04:03:37 proxmaster systemd: Listening on Device-mapper event daemon FIFOs.
Apr 21 04:03:37 proxmaster systemd: Listening on LVM2 poll daemon socket.
Apr 21 04:03:37 proxmaster systemd: Listening on RPCbind Server Activation Socket.
Apr 21 04:03:37 proxmaster systemd: Listening on Syslog Socket.
Apr 21 04:03:37 proxmaster systemd: Listening on fsck to fsckd communication Socket.
Apr 21 04:03:37 proxmaster systemd: Listening on initctl Compatibility Named Pipe.
Apr 21 04:03:37 proxmaster systemd: Listening on Journal Audit Socket.
Apr 21 04:03:37 proxmaster systemd: Listening on Journal Socket (/dev/log).
Apr 21 04:03:37 proxmaster systemd: Listening on Journal Socket.
Apr 21 04:03:37 proxmaster systemd: Listening on udev Control Socket.
Apr 21 04:03:37 proxmaster systemd: Listening on udev Kernel Socket.
Apr 21 04:03:37 proxmaster systemd: Mounting Huge Pages File System...
Apr 21 04:03:37 proxmaster systemd: Mounting POSIX Message Queue File System...
Apr 21 04:03:37 proxmaster systemd: Mounting NFSD configuration filesystem...
Apr 21 04:03:37 proxmaster systemd: Mounting RPC Pipe File System...
Apr 21 04:03:37 proxmaster systemd: Mounting Kernel Debug File System...
Apr 21 04:03:37 proxmaster systemd: Mounting Kernel Trace File System...
Apr 21 04:03:37 proxmaster systemd: Condition check resulted in Kernel Module supporting RPCSEC_GSS being skipped.
Apr 21 04:03:37 proxmaster systemd: Starting Set the console keyboard layout...
Apr 21 04:03:37 proxmaster systemd: Starting Create list of static device nodes for the current kernel...
Apr 21 04:03:37 proxmaster systemd: Starting Monitoring of LVM2 mirrors, snapshots etc. using dmeventd or progress polling...
Apr 21 04:03:37 proxmaster systemd: Starting Load Kernel Module configfs...
Apr 21 04:03:37 proxmaster systemd: Starting Load Kernel Module drm...
Apr 21 04:03:37 proxmaster systemd: Starting Load Kernel Module fuse...
Apr 21 04:03:37 proxmaster systemd: Condition check resulted in Set Up Additional Binary Formats being skipped.
Apr 21 04:03:37 proxmaster systemd: Condition check resulted in File System Check on Root Device being skipped.
Apr 21 04:03:37 proxmaster systemd: Starting Journal Service...
Apr 21 04:03:37 proxmaster systemd: Starting Load Kernel Modules...
Apr 21 04:03:37 proxmaster systemd: Starting Remount Root and Kernel File Systems...
Apr 21 04:03:37 proxmaster systemd: Starting Coldplug All udev Devices...
Apr 21 04:03:37 proxmaster systemd: Mounted Huge Pages File System.
Apr 21 04:03:37 proxmaster systemd: Mounted POSIX Message Queue File System.
Apr 21 04:03:37 proxmaster systemd: Mounted Kernel Debug File System.
Apr 21 04:03:37 proxmaster systemd: Mounted Kernel Trace File System.
Apr 21 04:03:37 proxmaster systemd: Finished Create list of static device nodes for the current kernel.
Apr 21 04:03:37 proxmaster systemd:
modprobe@configfs.service: Succeeded.
Apr 21 04:03:37 proxmaster systemd: Finished Load Kernel Module configfs.
Apr 21 04:03:37 proxmaster systemd: Finished Load Kernel Module fuse.



")

