I am using Proxmox on an Intel NUC8i5BEH as a home server running a couple of VMs. I'm new to Proxmox but decided to give it a try when I was moving my main Docker host from a Synology DS916+ to the NUC. Please ask me if you need additional information as this is my first forum post and I'm not sure what kind of info that is needed for you to help.
Proxmox is installed on an EXT4 volume running on a Kingston A2000 250GB NVMe drive with all the default installation options. There are a total of 3 VMs and one CT running. The load on the NUC is generally very low.
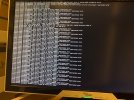
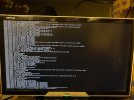
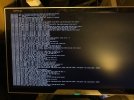
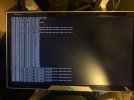
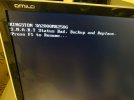
Ever since the start I've been having issues with the NVMe disk suddenly not responding. Proxmox suddenly hangs and none of the VMs or the Proxmox interface is reachable. When looking at the attached monitor the console is filled with errors about not being able to read or write to the disk (see attached pictures). The only way to make it work again is to cycle the power. Proxmox then boots up normally and everything is working again.
After a couple of days the same crash first happened again. Then it started happening more frequently. First the next day and then the next one within a couple of hours. When cycling the power the last time the disk had died completely and a SMART error was showing up when trying to boot.
I first suspected that it might be related to a bad NVMe disk, so I got a replacement disk on warranty and gave it another try. But the issues kept coming in a similar fashion as last time and last night my second NVMe disk died.
I spent some time when the second disk was new trying to force a crash to happen and I found that heavy disk usage (when rsyncing files to a network share for example) could cause a crash. Changing from a Samba share to an NFS share seemed to work better and the daily backup during night was running for a couple of weeks up until last night.
Any help with solving this issue would be very appreciated as I'm now going to buy a new disk for the third time. First question would then be if it could be some compatibility issue with the Kingston NVMe together with Proxmox in some way and if I should try a different brand?
Thanks!
Proxmox is installed on an EXT4 volume running on a Kingston A2000 250GB NVMe drive with all the default installation options. There are a total of 3 VMs and one CT running. The load on the NUC is generally very low.
Ever since the start I've been having issues with the NVMe disk suddenly not responding. Proxmox suddenly hangs and none of the VMs or the Proxmox interface is reachable. When looking at the attached monitor the console is filled with errors about not being able to read or write to the disk (see attached pictures). The only way to make it work again is to cycle the power. Proxmox then boots up normally and everything is working again.
After a couple of days the same crash first happened again. Then it started happening more frequently. First the next day and then the next one within a couple of hours. When cycling the power the last time the disk had died completely and a SMART error was showing up when trying to boot.
I first suspected that it might be related to a bad NVMe disk, so I got a replacement disk on warranty and gave it another try. But the issues kept coming in a similar fashion as last time and last night my second NVMe disk died.
I spent some time when the second disk was new trying to force a crash to happen and I found that heavy disk usage (when rsyncing files to a network share for example) could cause a crash. Changing from a Samba share to an NFS share seemed to work better and the daily backup during night was running for a couple of weeks up until last night.
Any help with solving this issue would be very appreciated as I'm now going to buy a new disk for the third time. First question would then be if it could be some compatibility issue with the Kingston NVMe together with Proxmox in some way and if I should try a different brand?
Thanks!