is the error always on the same block? In the same general area?
have you tried "dd if=/dev/sdh of=/dev/null" ?
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
is the error always on the same block? In the same general area?
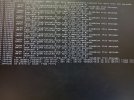
>> Seems to be different sectors each time. Please see the details below:
Mar 26 10:03:04 pve21atrs002 kernel: blk_update_request: I/O error, dev sdf, sector 43055279080 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:03:04 pve21atrs002 kernel: blk_update_request: I/O error, dev sdf, sector 43055277048 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:09:13 pve21atrs002 kernel: blk_update_request: I/O error, dev sdg, sector 43055279080 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:09:13 pve21atrs002 kernel: blk_update_request: I/O error, dev sdg, sector 43055277048 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:15:52 pve21atrs002 kernel: blk_update_request: I/O error, dev sdf, sector 43055277048 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:15:52 pve21atrs002 kernel: blk_update_request: I/O error, dev sdf, sector 43055279080 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:22:31 pve21atrs002 kernel: blk_update_request: I/O error, dev sdg, sector 43055279080 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 26 10:22:31 pve21atrs002 kernel: blk_update_request: I/O error, dev sdg, sector 43055277048 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 22 18:30:15 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055277616 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 22 18:36:23 pve21atrs002 kernel: blk_update_request: I/O error, dev sdi, sector 43055277616 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 22 18:42:34 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055277616 op 0x1: (WRITE) flags 0xca00 phys_seg 254 prio class 0
Mar 19 14:20:28 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055279472 op 0x1: (WRITE) flags 0xca00 phys_seg 2 prio class 0
Mar 19 14:20:28 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055279416 op 0x1: (WRITE) flags 0xca00 phys_seg 7 prio class 0
Mar 19 14:26:37 pve21atrs002 kernel: blk_update_request: I/O error, dev sdi, sector 43055279472 op 0x1: (WRITE) flags 0xca00 phys_seg 2 prio class 0
Mar 19 14:26:37 pve21atrs002 kernel: blk_update_request: I/O error, dev sdi, sector 43055279416 op 0x1: (WRITE) flags 0xca00 phys_seg 7 prio class 0
Mar 19 14:32:46 pve21atrs002 kernel: blk_update_request: I/O error, dev sdd, sector 43055279416 op 0x1: (WRITE) flags 0xca00 phys_seg 7 prio class 0
Mar 19 14:33:47 pve21atrs002 kernel: blk_update_request: I/O error, dev sdd, sector 43055279472 op 0x1: (WRITE) flags 0xca00 phys_seg 2 prio class 0
Mar 19 14:38:54 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055279416 op 0x1: (WRITE) flags 0xca00 phys_seg 7 prio class 0
Mar 19 14:40:57 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055279472 op 0x1: (WRITE) flags 0xca00 phys_seg 2 prio class 0
Mar 19 14:47:08 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055279416 op 0x1: (WRITE) flags 0xca00 phys_seg 7 prio class 0
Mar 19 14:47:08 pve21atrs002 kernel: blk_update_request: I/O error, dev sdh, sector 43055279472 op 0x1: (WRITE) flags 0xca00 phys_seg 2 prio class 0
have you tried "dd if=/dev/sdh of=/dev/null" ?
>> Have not tried it yet.. Should I do this during late hours when users have gone ?
")