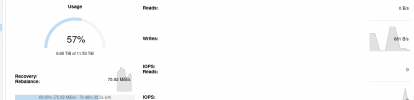Hallo,
im having a problem with my 5 Node Proxmox / Ceph Cluster.
The SSDs were full /near full and some OSDs gut into lock down. I've added two new SSDs but the Cluster wanted to Backfill and has now 6 of 22 OSDs offline and full.
I've stoped Backfilling to avoid more SSDs from becoming full / offline.
Is there Anyone who can help with that? The new SSDs are empty. I read that we need somehow to move data from the full SSD/OSDs but I dont know how.
Thank you.
Ceph health detail is giving:
pg 4.55 is stuck undersized for 95m, current state undersized+degraded+remapped+backfill_wait+peered, last acting [12]
pg 4.56 is stuck undersized for 114m, current state undersized+degraded+peered, last acting [13]
pg 4.5e is stuck undersized for 114m, current state stale+undersized+remapped+peered, last acting [7]
pg 4.5f is stuck undersized for 95m, current state active+undersized+degraded+remapped+backfill_wait, last acting [14,9]
pg 4.64 is stuck undersized for 2m, current state active+undersized+degraded+remapped+backfill_wait, last acting [14,1]
pg 4.67 is stuck undersized for 2m, current state active+undersized+degraded, last acting [16,3]
pg 4.6b is stuck undersized for 2m, current state active+undersized+remapped, last acting [5,0]
pg 4.6c is stuck undersized for 2m, current state active+undersized+remapped, last acting [16,12]
pg 4.6d is stuck undersized for 95m, current state active+undersized+remapped, last acting [13,0]
pg 4.6e is stuck undersized for 95m, current state active+undersized+degraded, last acting [2,0]
pg 4.6f is stuck undersized for 2m, current state active+undersized+degraded+remapped+backfill_wait, last acting [9,16]
pg 4.71 is stuck undersized for 43m, current state active+undersized+remapped, last acting [7,13]
pg 4.72 is stuck undersized for 2m, current state active+undersized+degraded+remapped+backfill_wait, last acting [14,8]
pg 4.75 is stuck undersized for 2m, current state active+undersized+degraded, last acting [0,16]
pg 4.76 is stuck undersized for 2m, current state active+undersized+degraded, last acting [5,9]
pg 4.7e is stuck undersized for 43m, current state active+undersized+remapped, last acting [1,7]
pg 4.7f is stuck undersized for 95m, current state undersized+degraded+peered, last acting [13]
[WRN] POOL_BACKFILLFULL: 6 pool(s) backfillfull
ceph health
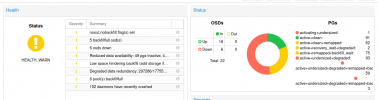
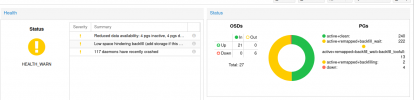
HEALTH_WARN noout,nobackfill flag(s) set; 5 backfillfull osd(s); 6 osds down; Reduced data availability: 49 pgs inactive, 4 pgs down, 1 pg stale; Low space hindering backfill (add storage if this doesn't resolve itself): 3 pgs backfill_toofull; Degraded data redundancy: 297286/1775595 objects degraded (16.743%), 198 pgs degraded, 247 pgs undersized; 6 pool(s) backfillfull; 102 daemons have recently crashed
im having a problem with my 5 Node Proxmox / Ceph Cluster.
The SSDs were full /near full and some OSDs gut into lock down. I've added two new SSDs but the Cluster wanted to Backfill and has now 6 of 22 OSDs offline and full.
I've stoped Backfilling to avoid more SSDs from becoming full / offline.
Is there Anyone who can help with that? The new SSDs are empty. I read that we need somehow to move data from the full SSD/OSDs but I dont know how.
Thank you.
Ceph health detail is giving:
pg 4.55 is stuck undersized for 95m, current state undersized+degraded+remapped+backfill_wait+peered, last acting [12]
pg 4.56 is stuck undersized for 114m, current state undersized+degraded+peered, last acting [13]
pg 4.5e is stuck undersized for 114m, current state stale+undersized+remapped+peered, last acting [7]
pg 4.5f is stuck undersized for 95m, current state active+undersized+degraded+remapped+backfill_wait, last acting [14,9]
pg 4.64 is stuck undersized for 2m, current state active+undersized+degraded+remapped+backfill_wait, last acting [14,1]
pg 4.67 is stuck undersized for 2m, current state active+undersized+degraded, last acting [16,3]
pg 4.6b is stuck undersized for 2m, current state active+undersized+remapped, last acting [5,0]
pg 4.6c is stuck undersized for 2m, current state active+undersized+remapped, last acting [16,12]
pg 4.6d is stuck undersized for 95m, current state active+undersized+remapped, last acting [13,0]
pg 4.6e is stuck undersized for 95m, current state active+undersized+degraded, last acting [2,0]
pg 4.6f is stuck undersized for 2m, current state active+undersized+degraded+remapped+backfill_wait, last acting [9,16]
pg 4.71 is stuck undersized for 43m, current state active+undersized+remapped, last acting [7,13]
pg 4.72 is stuck undersized for 2m, current state active+undersized+degraded+remapped+backfill_wait, last acting [14,8]
pg 4.75 is stuck undersized for 2m, current state active+undersized+degraded, last acting [0,16]
pg 4.76 is stuck undersized for 2m, current state active+undersized+degraded, last acting [5,9]
pg 4.7e is stuck undersized for 43m, current state active+undersized+remapped, last acting [1,7]
pg 4.7f is stuck undersized for 95m, current state undersized+degraded+peered, last acting [13]
[WRN] POOL_BACKFILLFULL: 6 pool(s) backfillfull
ceph health
HEALTH_WARN noout,nobackfill flag(s) set; 5 backfillfull osd(s); 6 osds down; Reduced data availability: 49 pgs inactive, 4 pgs down, 1 pg stale; Low space hindering backfill (add storage if this doesn't resolve itself): 3 pgs backfill_toofull; Degraded data redundancy: 297286/1775595 objects degraded (16.743%), 198 pgs degraded, 247 pgs undersized; 6 pool(s) backfillfull; 102 daemons have recently crashed