Hi everyone,
I have currently set up a Proxmox Hyper-Converged Ceph Cluster. VMs etc. are running as desired, so I am now testing crash scenarios.
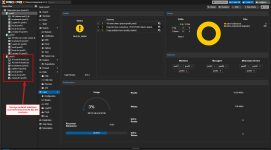
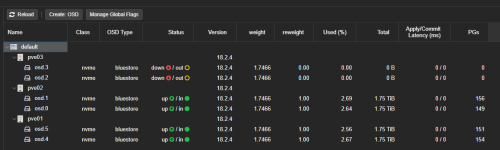
Here I encounter the following problem: If a node fails (storage network interfaces, see the current setup below), no rebalancing takes place and the VMs on the affected node are no longer accessible and migration to another node is also not possible.
If all network interfaces (HA and Ceph) fail, the migration works and everything continues to run as desired. If a node is shut down, the migration also works and everything continues to run as desired.
I am currently testing the crash scenario with my node “pve03”. I have attached a few screenshots for an overview.
Does anyone have a solution?
The setup is as follows:
- 3 nodes with 2 OSDs each.
- Full Mesh Routed Setup (with Fallback), two 10 GbE network interfaces each for Ceph
- one 1 GbE network interface each for HA
- PGs for the Ceph pools are configured according to optimal settings as per the pool overview
- Ceph version: 18.2.4
I have currently set up a Proxmox Hyper-Converged Ceph Cluster. VMs etc. are running as desired, so I am now testing crash scenarios.
Here I encounter the following problem: If a node fails (storage network interfaces, see the current setup below), no rebalancing takes place and the VMs on the affected node are no longer accessible and migration to another node is also not possible.
If all network interfaces (HA and Ceph) fail, the migration works and everything continues to run as desired. If a node is shut down, the migration also works and everything continues to run as desired.
I am currently testing the crash scenario with my node “pve03”. I have attached a few screenshots for an overview.
Does anyone have a solution?
The setup is as follows:
- 3 nodes with 2 OSDs each.
- Full Mesh Routed Setup (with Fallback), two 10 GbE network interfaces each for Ceph
- one 1 GbE network interface each for HA
- PGs for the Ceph pools are configured according to optimal settings as per the pool overview
- Ceph version: 18.2.4
Attachments
-
 2025-01-20 12_52_31-pve01 - Proxmox Virtual Environment und 7 weitere Seiten - Geschäftlich – ...png127.1 KB · Views: 8
2025-01-20 12_52_31-pve01 - Proxmox Virtual Environment und 7 weitere Seiten - Geschäftlich – ...png127.1 KB · Views: 8 -
 2025-01-20 12_53_59-pve01 - Proxmox Virtual Environment und 7 weitere Seiten - Geschäftlich – ...png18.5 KB · Views: 8
2025-01-20 12_53_59-pve01 - Proxmox Virtual Environment und 7 weitere Seiten - Geschäftlich – ...png18.5 KB · Views: 8 -
 2025-01-20 12_55_23-pve01 - Proxmox Virtual Environment und 7 weitere Seiten - Geschäftlich – ...png30.8 KB · Views: 8
2025-01-20 12_55_23-pve01 - Proxmox Virtual Environment und 7 weitere Seiten - Geschäftlich – ...png30.8 KB · Views: 8
