root@SRV2:~# iptables-save
ip addr
ip route
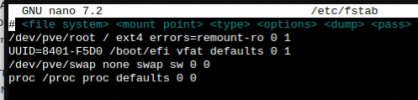
cat /etc/network/interfaces
# Generated by iptables-save v1.8.9 on Mon Jul 31 11:44:40 2023
*raw
:PREROUTING ACCEPT [40909715:9347983927]
:OUTPUT ACCEPT [39632043:8416420367]
COMMIT
# Completed on Mon Jul 31 11:44:40 2023
# Generated by iptables-save v1.8.9 on Mon Jul 31 11:44:40 2023
*filter
:INPUT ACCEPT [40365502:9253155413]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [39632043:8416420367]
COMMIT
# Completed on Mon Jul 31 11:44:40 2023
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp37s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master vmbr2 state UP group default qlen 1000
link/ether 04:7c:16:5b:80:4c brd ff:ff:ff:ff:ff:ff
3: enp42s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master vmbr1 state UP group default qlen 1000
link/ether 04:7c:16:5b:80:4b brd ff:ff:ff:ff:ff:ff
4: enp35s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6c:b3:11:3d:4d:5e brd ff:ff:ff:ff:ff:ff
5: enp36s0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6c:b3:11:3d:4d:5e brd ff:ff:ff:ff:ff:ff
6: vmbr1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 04:7c:16:5b:80:4b brd ff:ff:ff:ff:ff:ff
inet 192.168.1.21/24 scope global vmbr1
valid_lft forever preferred_lft forever
inet6 fe80::67c:16ff:fe5b:804b/64 scope link
valid_lft forever preferred_lft forever
7: vmbr2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 04:7c:16:5b:80:4c brd ff:ff:ff:ff:ff:ff
inet6 fe80::67c:16ff:fe5b:804c/64 scope link
valid_lft forever preferred_lft forever
8: tap104i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr104i0 state UNKNOWN group default qlen 1000
link/ether 92:07:94:fb:18:6f brd ff:ff:ff:ff:ff:ff
9: fwbr104i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:ff:73:90:e4:de brd ff:ff:ff:ff:ff:ff
10: fwpr104p0@fwln104i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr2 state UP group default qlen 1000
link/ether 52:25:a0:55:a9:7e brd ff:ff:ff:ff:ff:ff
11: fwln104i0@fwpr104p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr104i0 state UP group default qlen 1000
link/ether 62:80:66:a3:09:42 brd ff:ff:ff:ff:ff:ff
12: tap105i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr105i0 state UNKNOWN group default qlen 1000
link/ether 4a:f3:39:db:f7:a9 brd ff:ff:ff:ff:ff:ff
13: fwbr105i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 32:4a:75:51:12:86 brd ff:ff:ff:ff:ff:ff
14: fwpr105p0@fwln105i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr1 state UP group default qlen 1000
link/ether da:89:d0:87:bc:2e brd ff:ff:ff:ff:ff:ff
15: fwln105i0@fwpr105p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr105i0 state UP group default qlen 1000
link/ether 22:6d:74:fc:43:46 brd ff:ff:ff:ff:ff:ff
16: tap106i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr106i0 state UNKNOWN group default qlen 1000
link/ether be:76:6e:2c:62:6d brd ff:ff:ff:ff:ff:ff
17: fwbr106i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 8a:b8:15:d1:3a:66 brd ff:ff:ff:ff:ff:ff
18: fwpr106p0@fwln106i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr2 state UP group default qlen 1000
link/ether 9e:85:d4:5f:72:f0 brd ff:ff:ff:ff:ff:ff
19: fwln106i0@fwpr106p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr106i0 state UP group default qlen 1000
link/ether a2:3c:d3:1a:2b:84 brd ff:ff:ff:ff:ff:ff
20: tap107i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr107i0 state UNKNOWN group default qlen 1000
link/ether 0a:93:85:e6:a4:46 brd ff:ff:ff:ff:ff:ff
21: fwbr107i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 5e:91:a8:d7:00:27 brd ff:ff:ff:ff:ff:ff
22: fwpr107p0@fwln107i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr1 state UP group default qlen 1000
link/ether 1a:b5:f1:bd:6f:96 brd ff:ff:ff:ff:ff:ff
23: fwln107i0@fwpr107p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr107i0 state UP group default qlen 1000
link/ether 1e:61:8e:00:2b:0d brd ff:ff:ff:ff:ff:ff
default via 192.168.1.1 dev vmbr1 proto kernel onlink
192.168.1.0/24 dev vmbr1 proto kernel scope link src 192.168.1.21
# network interface settings; autogenerated
# Please do NOT modify this file directly, unless you know what
# you're doing.
#
# If you want to manage parts of the network configuration manually,
# please utilize the 'source' or 'source-directory' directives to do
# so.
# PVE will preserve these directives, but will NOT read its network
# configuration from sourced files, so do not attempt to move any of
# the PVE managed interfaces into external files!
auto lo
iface lo inet loopback
iface enp37s0 inet manual
#ONBOARD NIC 1GBE
iface enp42s0 inet manual
#ONBOARD NIC 2.5GBE
iface enp35s0 inet manual
iface enp36s0 inet manual
auto vmbr1
iface vmbr1 inet static
address 192.168.1.21/24
gateway 192.168.1.1
bridge-ports enp42s0
bridge-stp off
bridge-fd 0
#ONBOARD NIC 2.5GBE
auto vmbr2
iface vmbr2 inet manual
bridge-ports enp37s0
bridge-stp off
bridge-fd 0
#ONBOARD NIC 1GBE