Hi,
we using Proxmox updated version: 8.3.2 (we did now upgrade from 7.4.x) in env with Broadcom BCM57504 NetXtreme-E 10Gb/25Gb on Dell Server
we using remote iscsi over iser storage and pbs for backups, the problem is that each time we have backup for disks > 100Gb it's stop, Hangs the server and shows the following error: bnxt_en Failed to create HW QP
(attached as screenshot)
we have seen the Threads
and
but in our case we don't want to disable the iSER/RDMA support since it's in use, we did firmware update to the NIC, now it's v231.1.162.1, didn't help any advice?
Kind Regards,
we using Proxmox updated version: 8.3.2 (we did now upgrade from 7.4.x) in env with Broadcom BCM57504 NetXtreme-E 10Gb/25Gb on Dell Server
we using remote iscsi over iser storage and pbs for backups, the problem is that each time we have backup for disks > 100Gb it's stop, Hangs the server and shows the following error: bnxt_en Failed to create HW QP
(attached as screenshot)
we have seen the Threads
We recently uploaded a 6.8 kernel into our repositories, it will be used as new default kernel in the next Proxmox VE 8.2 point release (Q2'2024).
This follows our tradition of upgrading the Proxmox VE kernel to match the current Ubuntu version until we reach an (Ubuntu) LTS release. This kernel is based on the upcoming Ubuntu 24.04 Noble release.
We have run this kernel on some parts of our test setups over the last few days without any notable issues.
How to install:
This follows our tradition of upgrading the Proxmox VE kernel to match the current Ubuntu version until we reach an (Ubuntu) LTS release. This kernel is based on the upcoming Ubuntu 24.04 Noble release.
We have run this kernel on some parts of our test setups over the last few days without any notable issues.
How to install:
- Ensure that either the pve-no-subscription or pvetest repository is set up correctly.
You can...
- t.lamprecht
- kernel 6.8
- Replies: 221
- Forum: Proxmox VE: Installation and configuration

We had some issues with some broadcom nics going down after update to 6.8
Workaround: NICs go up if you do a
FIX: Update Broadcom Firmware to latest firmware and blacklist their "beautiful" infiniband-driver
This will update ALL YOUR Broadcom-Network Cards to their latest firmware (live) (but reboot needed after it):
Workaround: NICs go up if you do a
service networking restartFIX: Update Broadcom Firmware to latest firmware and blacklist their "beautiful" infiniband-driver
This will update ALL YOUR Broadcom-Network Cards to their latest firmware (live) (but reboot needed after it):
apt install unzip
cat << 'EOF' > bcm-nic-update.sh
wget https://www.thomas-krenn.com/redx/tools/mb_download.php/ct.YuuHGw/mid.y9b3b4ba2bf7ab3b8/bnxtnvm.zip
unzip bnxtnvm.zip
chmod +x bnxtnvm
for i in $(./bnxtnvm listdev...
- jsterr
- broadcom kernel 6.8 network p225g p425g pve 8.2
- Replies: 64
- Forum: Proxmox VE: Installation and configuration
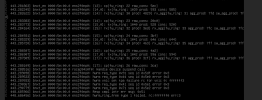
Code:
# pveversion
pve-manager/8.3.2/3e76eec21c4a14a7 (running kernel: 6.8.12-5-pve)
Code:
root@testnode1:~# ethtool -i ens1f0np0
driver: bnxt_en
version: 6.8.12-5-pve
firmware-version: 231.0.154.0/pkg 231.1.162.1
expansion-rom-version:
bus-info: 0000:5e:00.0
supports-statistics: yes
supports-test: yes
supports-eeprom-access: yes
supports-register-dump: yes
supports-priv-flags: no
root@testnode1:~#Kind Regards,