Hi.
I'm having problems with replication jobs on our proxmox server.
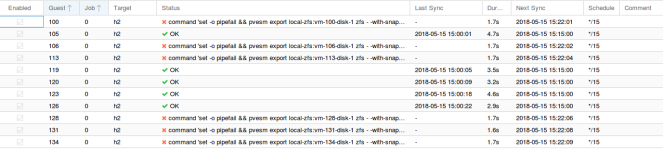
I'm getting:
When pasting that command directly into terminal I'm getting:
Any ideas what could be the problem?
I'm having problems with replication jobs on our proxmox server.
I'm getting:
Code:
2018-05-15 11:54:02 100-0: end replication job with error: command 'set -o pipefail && pvesm export local-zfs:vm-100-disk-1 zfs - -with-snapshots 1 -snapshot __replicate_100-0_1526378041__ | /usr/bin/ssh -o 'BatchMode=yes' -o 'HostKeyAlias=h2' root@IP -- pvesm import local-zfs:vm-100-disk-1 zfs - -with-snapshots 1' failed: exit code 255When pasting that command directly into terminal I'm getting:
Code:
volume 'rpool/data/vm-100-disk-1' already exists
cannot send rpool/data/vm-100-disk-1@__replicate_100-0_1526377082__ recursively: snapshot rpool/data/vm-100-disk-1@__replicate_100-0_1526377082__ does not exist
command 'zfs send -Rpv -- rpool/data/vm-100-disk-1@__replicate_100-0_1526377082__' failed: exit code 1Any ideas what could be the problem?