Hi,
I'm struggling with a problem regarding backups of Proxmox VE using Veeam Backup & Replication Community Edition for a few months now. Actually, the problem seems to be related to the start of the Veeam-Worker VM initiated by the Veeam Backup & Replication solution.
I believe the problem may have started after upgrading Proxmox VE from 8.2 to 8.3, but I'm not entirely sure as the problem isn't permanently there.
There is a daily backup job. It can work several days in a row without any problem. Then, one day I get a backup failed message and when I check the PVE webgui, I can see a still running task for starting VM 101, which is the Veeam-Worker VM. The task may run for 10's of hours without actually starting the VM. In the VM overview, the VM remains in a stopped state. Subsequent Veeam backups will fail until the task is stopped manually. Once stopped manually the output in the task window is as follows:
And in the system log:
If I test the worker VM in Veeam, the test will be successful every time (each time the worker VM is started successfully, tested and then stopped). But planned and manual backups tend to fail possibly in about 20 to 30 % of all cases. The PVE server is far away from running on it's ressource limits (average CPU <10 %, max CPU <30 %, RAM and disk usage <50 %).
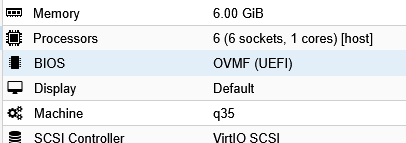
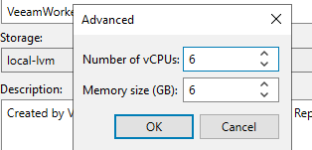
Regarding VM ressource allocations for Veeam and worker VM, the recommendations have been applied.
To overcome this situation I have tried various steps:
Any help is be very appreciated and I'm happy to provide any output that may be helpful to find the issue.
Just in case the question arises as to why not use Proxmox Backup Server: According to the best practices described for PBS, our network infrastructure doesn't meet several of the criterias. I tested it and it was much too slow unfortunately.
I'm struggling with a problem regarding backups of Proxmox VE using Veeam Backup & Replication Community Edition for a few months now. Actually, the problem seems to be related to the start of the Veeam-Worker VM initiated by the Veeam Backup & Replication solution.
I believe the problem may have started after upgrading Proxmox VE from 8.2 to 8.3, but I'm not entirely sure as the problem isn't permanently there.
There is a daily backup job. It can work several days in a row without any problem. Then, one day I get a backup failed message and when I check the PVE webgui, I can see a still running task for starting VM 101, which is the Veeam-Worker VM. The task may run for 10's of hours without actually starting the VM. In the VM overview, the VM remains in a stopped state. Subsequent Veeam backups will fail until the task is stopped manually. Once stopped manually the output in the task window is as follows:
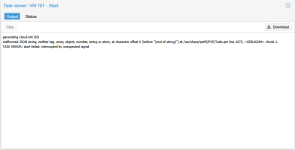
Code:
generating cloud-init ISO
malformed JSON string, neither tag, array, object, number, string or atom, at character offset 0 (before "(end of string)") at /usr/share/perl5/PVE/Tools.pm line 1073, <GEN12937> chunk 1.
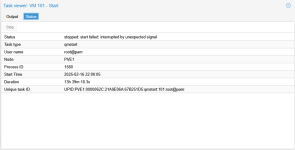
TASK ERROR: start failed: interrupted by unexpected signalAnd in the system log:
Code:
pvedaemon[1335357]: malformed JSON string, neither tag, array, object, number, string or atom, at character offset 0 (before "(end of string)") at /usr/share/perl5/PVE/Tools.pm line 1073, <GEN19863> chunk 1.If I test the worker VM in Veeam, the test will be successful every time (each time the worker VM is started successfully, tested and then stopped). But planned and manual backups tend to fail possibly in about 20 to 30 % of all cases. The PVE server is far away from running on it's ressource limits (average CPU <10 %, max CPU <30 %, RAM and disk usage <50 %).
Regarding VM ressource allocations for Veeam and worker VM, the recommendations have been applied.
To overcome this situation I have tried various steps:
- Update newly appearing PVE/Debian packages several times. right now I'm on PVE 8.3.3 with all available updates from enterprise repository applied as of today.
- Reboot the whole PVE server.
- Update Veeam Backup & Replication Community Edition to latest available version 12.3.0.310 dated December 3, 2024 (so after PVE 8.3 release).
- Delete and let Veeam recreate the worker VM with latest Veeam version.
- Update Windows 11 Pro 23H2 to 24H2 - this is the OS where the Veeam software is installed on.
Any help is be very appreciated and I'm happy to provide any output that may be helpful to find the issue.
Just in case the question arises as to why not use Proxmox Backup Server: According to the best practices described for PBS, our network infrastructure doesn't meet several of the criterias. I tested it and it was much too slow unfortunately.
Last edited: