Hey guys,
I'm new here on the forum and I'm looking for help with a problem that I've been facing for some time, but I haven't found people who have managed to solve it.
I'm Brazilian and I'm using a translator, so some things may be poorly translated.
I have a backup of my PVE virtual machines that are local, these backups are made by the Proxmox Backup Server (it is also local). What happens is that I've had some machines that had problems and I tried to restore the backup, however, I always get the error below, after getting close to 20% restoration:
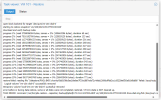
restore failed: reading file "/datastore/POOL-BKP/.chunks/0bb5/0bb5ea2de6ee7f33a1887ede72c4deb1268dc9fbd2cc1d5228e6f20a01b8bb8b" failed: Input/output error (os error 5)
Logical volume "vm-101-disk-0" successfully removed
temporary volume 'local-lvm:vm-101-disk-0' sucessfully removed
error before or during data restore, some or all disks were not completely restored. VM 101 state is NOT cleaned up.
TASK ERROR: command '/usr/bin/pbs-restore --repository backup@pbs@172.31.0.10: POOL-BKP vm/100/2024-05-07T03:00:02Z drive-ide0.img.fidx /dev/ pve/vm-101-disk-0 --verbose --format raw --skip-zero' failed: exit code 255
Anyone who has been through this could help me resolve it or perhaps instruct me on how to proceed. (I've already tried to reset 3 machines in the past, different periods and different operating systems, and I always get this error)
Versions of virtualization and backup systems:
Proxmox Virtual Environment 7.1-10
Proxmox Backup Server 3.1-2
I'm new here on the forum and I'm looking for help with a problem that I've been facing for some time, but I haven't found people who have managed to solve it.
I'm Brazilian and I'm using a translator, so some things may be poorly translated.
I have a backup of my PVE virtual machines that are local, these backups are made by the Proxmox Backup Server (it is also local). What happens is that I've had some machines that had problems and I tried to restore the backup, however, I always get the error below, after getting close to 20% restoration:
restore failed: reading file "/datastore/POOL-BKP/.chunks/0bb5/0bb5ea2de6ee7f33a1887ede72c4deb1268dc9fbd2cc1d5228e6f20a01b8bb8b" failed: Input/output error (os error 5)
Logical volume "vm-101-disk-0" successfully removed
temporary volume 'local-lvm:vm-101-disk-0' sucessfully removed
error before or during data restore, some or all disks were not completely restored. VM 101 state is NOT cleaned up.
TASK ERROR: command '/usr/bin/pbs-restore --repository backup@pbs@172.31.0.10: POOL-BKP vm/100/2024-05-07T03:00:02Z drive-ide0.img.fidx /dev/ pve/vm-101-disk-0 --verbose --format raw --skip-zero' failed: exit code 255
Anyone who has been through this could help me resolve it or perhaps instruct me on how to proceed. (I've already tried to reset 3 machines in the past, different periods and different operating systems, and I always get this error)
Versions of virtualization and backup systems:
Proxmox Virtual Environment 7.1-10
Proxmox Backup Server 3.1-2
Attachments
Last edited:


