Hallo,
wir haben einen Proxmox Cluster mit 3 Nodes installiert.
Jede Maschine hat 128 GB RAM und 2 ssd für das Proxmox System installiert.
Zusätzlich sind in jeder Maschine 2 physikalische CPU mit je mindestens 6 Cores installiert.
Für das CEPH System sind pro Server je 2 SSD's der Modellnummer XA1920LE10063 verbaut.
Die Platten sind direkt an einen HBA Angeschlossen.
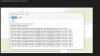
Tests mit FIO ergeben gute Werte sowohl bei Schreib als auch bei Lesezugriffen.
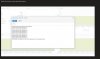
Allerdings bekommen wir die Fehlermeldung "trying to acquire cfs lock 'storage-vms' beim Versuch eine VM auf eine andere Node zu klonen.
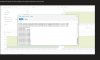
Beim Clonen einer VM auf dieselbe Node haben wir extrem langsame Zugriffszeiten.
Wird der Task gestoppt bleibt das "removen" de images "hängen".
Testweise habe ich dann eine zuvor erstelle 300 GB Festplatte über die Gui gelöscht. Dies dauerte ca. 3 Minuten!
Wir bitten Sie hiermit um Unterstützung bei der Problematik da wir mittlerweile mit dem Setup für unser Rechenzentrum auf Grund der Analyse und Recherche (leider erfolglos) schon sehr in Zeitverzug sind.
Im Anhang finden Sie die Screenshots der Fehler sowie den output vom FIO Test.
Sollten weitere Informationen zu unserem Setup nötig sein reichen wir dieses natürlich gerne nach!
Ich bedanke mich im Vorhinein für Ihre Unterstützung
wir haben einen Proxmox Cluster mit 3 Nodes installiert.
Jede Maschine hat 128 GB RAM und 2 ssd für das Proxmox System installiert.
Zusätzlich sind in jeder Maschine 2 physikalische CPU mit je mindestens 6 Cores installiert.
Für das CEPH System sind pro Server je 2 SSD's der Modellnummer XA1920LE10063 verbaut.
Die Platten sind direkt an einen HBA Angeschlossen.
Tests mit FIO ergeben gute Werte sowohl bei Schreib als auch bei Lesezugriffen.
Allerdings bekommen wir die Fehlermeldung "trying to acquire cfs lock 'storage-vms' beim Versuch eine VM auf eine andere Node zu klonen.
Beim Clonen einer VM auf dieselbe Node haben wir extrem langsame Zugriffszeiten.
Wird der Task gestoppt bleibt das "removen" de images "hängen".
Testweise habe ich dann eine zuvor erstelle 300 GB Festplatte über die Gui gelöscht. Dies dauerte ca. 3 Minuten!
Wir bitten Sie hiermit um Unterstützung bei der Problematik da wir mittlerweile mit dem Setup für unser Rechenzentrum auf Grund der Analyse und Recherche (leider erfolglos) schon sehr in Zeitverzug sind.
Im Anhang finden Sie die Screenshots der Fehler sowie den output vom FIO Test.
Sollten weitere Informationen zu unserem Setup nötig sein reichen wir dieses natürlich gerne nach!
Ich bedanke mich im Vorhinein für Ihre Unterstützung
")