Hi
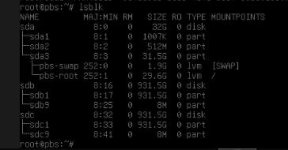
I am running PBS as a VM and I got 2 hdds in Mirror configuration.
At boot the host starts up as normal but the PBS VM hangs at "importing pools" when loading so I cannot SSH to it or communicate via the GUI.
At the host the pool is not listed but the disks are OK and I can reach it through the GUI.
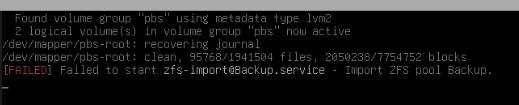
"zpool status" gives me nothing, "zfs import -f "poolname" freezes or it hangs but "zfs import" I get the following output whern trying to import manually:
I am running PBS as a VM and I got 2 hdds in Mirror configuration.
At boot the host starts up as normal but the PBS VM hangs at "importing pools" when loading so I cannot SSH to it or communicate via the GUI.
At the host the pool is not listed but the disks are OK and I can reach it through the GUI.
"zpool status" gives me nothing, "zfs import -f "poolname" freezes or it hangs but "zfs import" I get the following output whern trying to import manually:
zpool import
pool: Backups
id: 2818162679070632605
state: ONLINE
status: Some supported features are not enabled on the pool.
(Note that they may be intentionally disabled if the
'compatibility' property is set.)
action: The pool can be imported using its name or numeric identifier, though
some features will not be available without an explicit 'zpool upgrade'.
config:
Backups ONLINE
mirror-0 ONLINE
sdb ONLINE
sda ONLINE
root@pve5:~# zpool import -f -d /dev/disk/by-id/2818162679070632605
no pools available to import
root@pve5:~# zpool import -f -d /dev/disk/by-id/Backups
no pools available to import
Last edited:
")